StepFun AI Releases Step-Audio-EditX: A New Open-Source 3B LLM-Grade Audio Editing Model Excelling at Expressive and Iterative Audio Editing
How can speech editing become as direct and controllable as simply rewriting a line of text? StepFun AI has open sourced Step-Audio-EditX, a 3B parameter LLM based audio model that turns expressive speech editing into a token level text like operation, instead of a waveform level signal processing task.
Why developers care about controllable TTS?
Most zero shot TTS systems copy emotion, style, accent, and timbre directly from a short reference audio. They can sound natural, but control is weak. Style prompts in text help only for in domain voices, and the cloned voice often ignores the requested emotion or speaking style.
Past work tries to disentangle factors with extra encoders, adversarial losses, or complex architectures. Step-Audio-EditX keeps a relatively entangled representation and instead changes the data and post training objective. The model learns control by seeing many pairs and triplets where text is fixed, but one attribute changes with a large margin.
Architecture, dual codebook tokenizer plus compact audio LLM
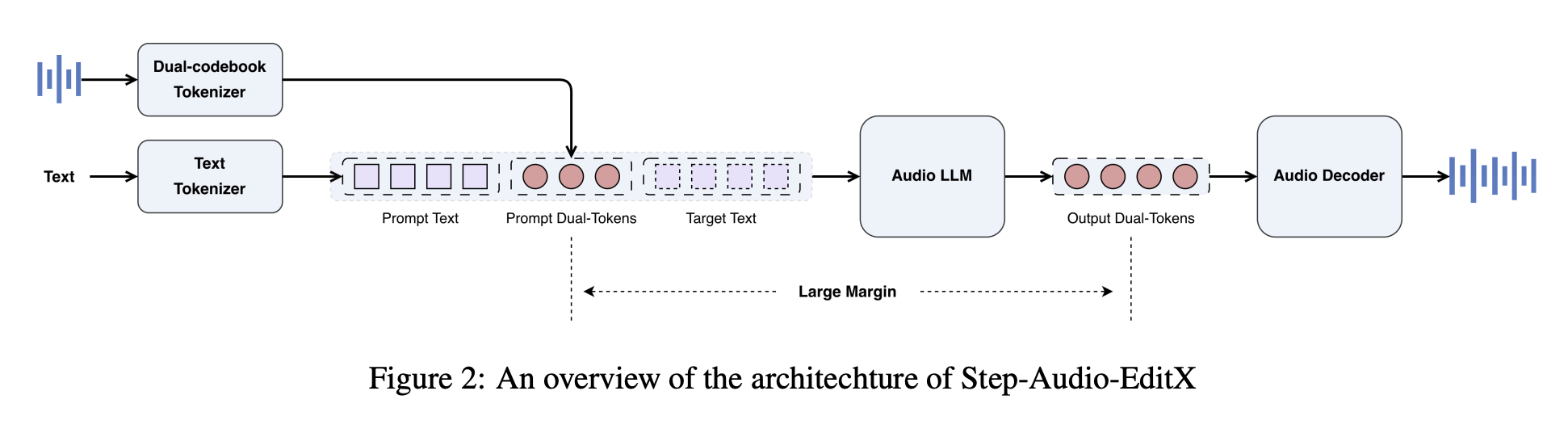
Step-Audio-EditX reuses the Step-Audio dual codebook tokenizer. Speech is mapped into two token streams, a linguistic stream at 16.7 Hz with a 1024 entry codebook, and a semantic stream at 25 Hz with a 4096 entry codebook. Tokens are interleaved with a 2 to 3 ratio. The tokenizer keeps prosody and emotion information, so it is not fully disentangled.
On top of this tokenizer, the StepFun research team builds a 3B parameter audio LLM. The model is initialized from a text LLM, then trained on a blended corpus with a 1 to 1 ratio of pure text and dual codebook audio tokens in chat style prompts. The audio LLM reads text tokens, audio tokens, or both, and always generates dual codebook audio tokens as output.
A separate audio decoder handles reconstruction. A diffusion transformer based flow matching module predicts Mel spectrograms from audio tokens, reference audio, and a speaker embedding, and a BigVGANv2 vocoder converts Mel spectrograms to waveform. The flow matching module is trained on about 200000 hours of high quality speech, which improves pronunciation and timbre similarity.
Large margin synthetic data instead of complicated encoders
The key idea is large margin learning. The model is post trained on triplets and quadruplets that keep text fixed and change only one attribute with a clear gap.
For zero shot TTS, Step-Audio-EditX uses a high quality in house dataset, mainly Chinese and English, with a small amount of Cantonese and Sichuanese, and about 60000 speakers. The data covers wide intra speaker and inter speaker variation in style and emotion.(arXiv)
For emotion and speaking style editing, the team builds synthetic large margin triplets (text, audio neutral, audio emotion or style). Voice actors record about 10 second clips for each emotion and style. StepTTS zero shot cloning then produces neutral and emotional versions for the same text and speaker. A margin scoring model, trained on a small human labeled set, scores pairs on a 1 to 10 scale, and only samples with score at least 6 are kept.
Paralinguistic editing, which covers breathing, laughter, filled pauses and other tags, uses a semi synthetic strategy on top of the NVSpeech dataset. The research team builds quadruplets where the target is the original NVSpeech audio and transcript, and the input is a cloned version with tags removed from the text. This gives time domain editing supervision without a margin model.
Reinforcement learning data uses two preference sources. Human annotators rate 20 candidates per prompt on a 5 point scale for correctness, prosody, and naturalness, and pairs with margin greater than 3 are kept. A comprehension model scores emotion and speaking style on a 1 to 10 scale, and pairs with margin greater than 8 are kept.
Post training, SFT plus PPO on token sequences
Post training has two stages, supervised fine tuning followed by PPO.
In supervised fine tuning, system prompts define zero shot TTS and editing tasks in a unified chat format. For TTS, the prompt waveform is encoded to dual codebook tokens, converted to string form, and inserted into the system prompt as speaker information. The user message is the target text, and the model returns new audio tokens. For editing, the user message includes original audio tokens plus a natural language instruction, and the model outputs edited tokens.
Reinforcement learning then refines instruction following. A 3B reward model is initialized from the SFT checkpoint and trained with Bradley Terry loss on large margin preference pairs. The reward is computed directly on dual codebook token sequences, without decoding to waveform. PPO training uses this reward model, a clip threshold, and a KL penalty to balance quality and deviation from the SFT policy.
Step-Audio-Edit-Test, iterative editing and generalization
To quantify control, the research team introduced Step-Audio-Edit-Test. It uses Gemini 2.5 Pro as an LLM as a judge to evaluate emotion, speaking style, and paralinguistic accuracy. The benchmark has 8 speakers, drawn from Wenet Speech4TTS, GLOBE V2, and Libri Light, with 4 speakers per language.
The emotion set has 5 categories with 50 Chinese and 50 English prompts per category. The speaking style set has 7 styles with 50 prompts per language per style. The paralinguistic set has 10 labels such as breathing, laughter, surprise oh, and uhm, with 50 prompts per label and language.
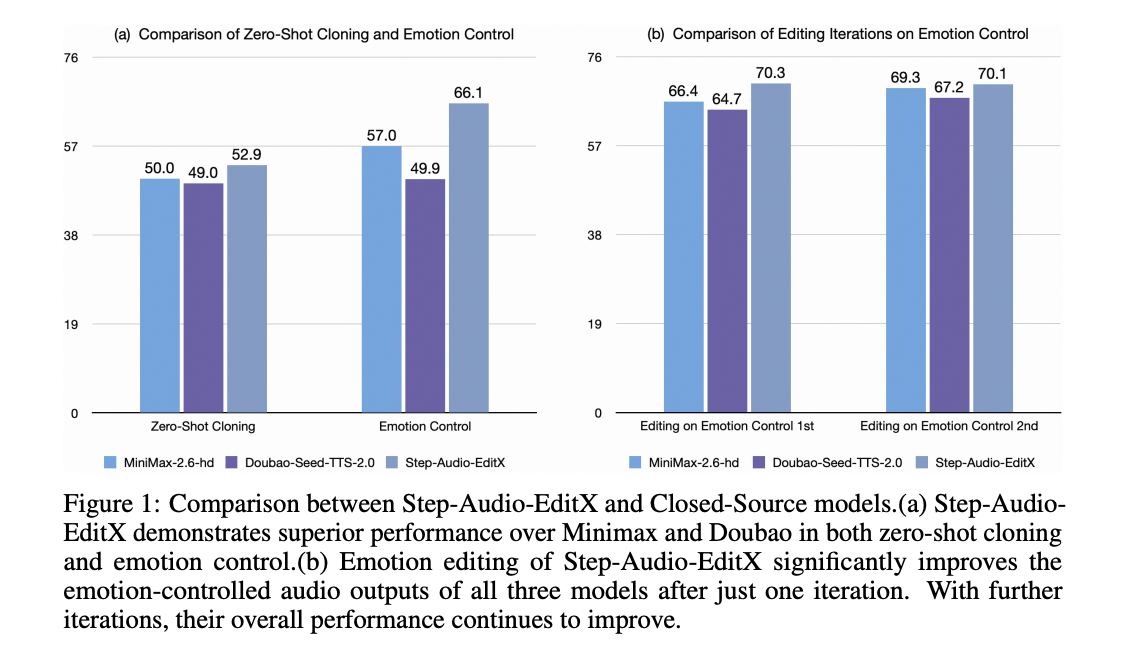
Editing is evaluated iteratively. Iteration 0 is the initial zero shot clone. Then the model applies 3 rounds of editing with text instructions. In Chinese, emotion accuracy rises from 57.0 at iteration 0 to 77.7 at iteration 3. Speaking style accuracy rises from 41.6 to 69.2. English shows similar behavior, and a prompt fixed ablation, where the same prompt audio is used for all iterations, still improves accuracy, which supports the large margin learning hypothesis.

The same editing model is applied to four closed source TTS systems, GPT 4o mini TTS, ElevenLabs v2, Doubao Seed TTS 2.0, and MiniMax speech 2.6 hd. For all of them, one editing iteration with Step-Audio-EditX improves both emotion and style accuracy, and further iterations continue to help.
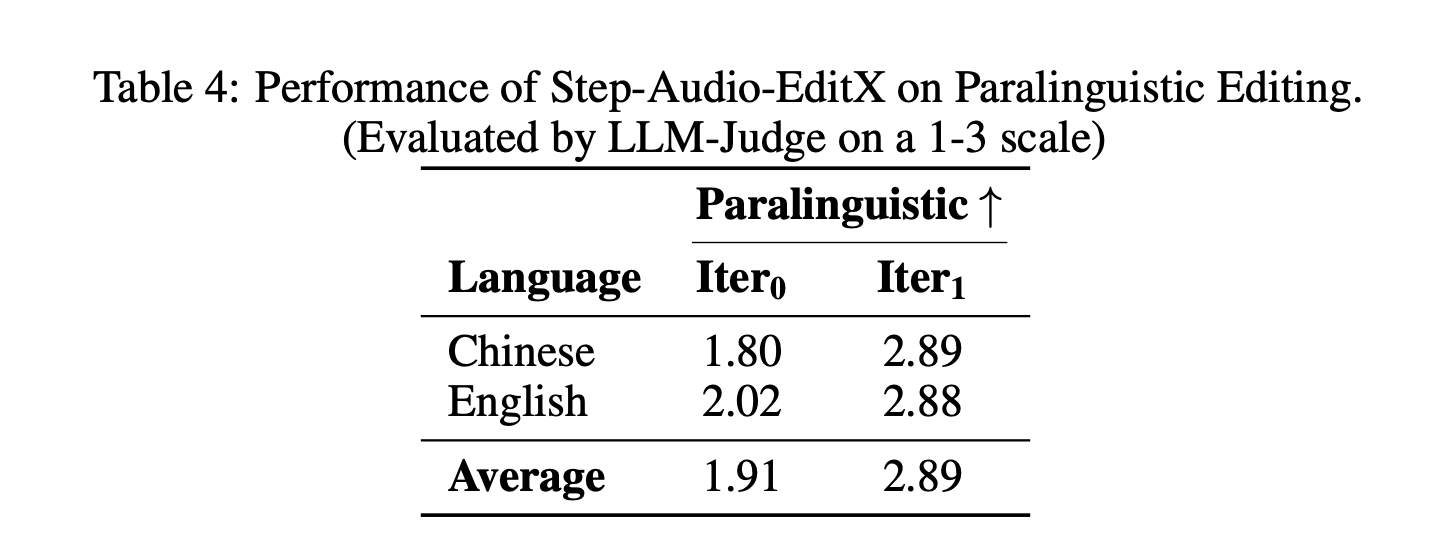
Paralinguistic editing is scored on a 1 to 3 scale. The average score rises from 1.91 at iteration 0 to 2.89 after a single edit, in both Chinese and English, which is comparable to native paralinguistic synthesis in strong commercial systems.
Key Takeaways
- Step Audio EditX uses a dual codebook tokenizer and a 3B parameter audio LLM so it can treat speech as discrete tokens and edit audio in a text like way.
- The model relies on large margin synthetic data for emotion, speaking style, paralinguistic cues, speed, and noise, rather than adding extra disentangling encoders.
- Supervised fine tuning plus PPO with a token level reward model aligns the audio LLM to follow natural language editing instructions for both TTS and editing tasks.
- The Step Audio Edit Test benchmark with Gemini 2.5 Pro as a judge shows clear accuracy gains over 3 editing iterations for emotion, style, and paralinguistic control in both Chinese and English.
- Step Audio EditX can post process and improve speech from closed source TTS systems, and the full stack, including code and checkpoints, is available as open source for developers.
Step Audio EditX is a precise step forward in controllable speech synthesis, because it keeps the Step Audio tokenizer, adds a compact 3B audio LLM, and optimizes control through large margin data and PPO. The introduction of Step Audio Edit Test with Gemini 2.5 Pro as a judge makes the evaluation story concrete for emotion, speaking style, and paralinguistic control, and the open release lowers the barrier for practical audio editing research. Overall, this release makes audio editing feel much closer to text editing.
Check out the Paper, Repo and Model Weights. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.