Generalist AI Introduces GEN-θ: A New Class of Embodied Foundation Models Built for Multimodal Training Directly on High-Fidelity Raw Physical Interaction
How do you build a single model that can learn physical skills from chaotic real world robot data without relying on simulation? Generalist AI has unveiled GEN-θ, a family of embodied foundation models trained directly on high fidelity raw physical interaction data instead of internet video or simulation. The system is built to establish scaling laws for robotics in the same way that large language models did for text, but now grounded in continuous sensorimotor streams from real robots operating in homes, warehouses and workplaces.
Harmonic Reasoning, thinking and acting in real time
GEN-θ is introduced as an embodied foundation model architecture that builds on the strengths of vision and language models, and extends them with native support for human level reflexes and physical commonsense. The core feature is Harmonic Reasoning, where the model is trained to think and act at the same time over asynchronous, continuous time streams of sensing and acting tokens.
This design targets a robotics specific constraint. Language models can simply spend more time thinking before replying, but robots must act while physics continues to evolve. Harmonic Reasoning creates a harmonic interplay between sensing and acting streams so that GEN-θ can scale to very large model sizes without depending on System1-System2 architectures or heavy inference time guidance controllers.
GEN-θ is explicitly cross embodiment. The same architecture runs on different robots and has been tested on 6DoF, 7DoF and 16+DoF semi humanoid systems, which lets a single pre-training run serve heterogeneous fleets.
Surpassing the intelligence threshold in robotics
The Generalist AI team reports a phase transition in capability as GEN-θ scales in a high data regime. Their scaling research experiment also show that the models must be large enough to absorb vast amounts of physical interaction data.
Their behaviors are as follows:
- 1B models struggle to absorb complex and diverse sensorimotor data during pretraining and their weights stop absorbing new information, which the research team describe as ossification.
- 6B models start to benefit from pretraining and show strong multi task capabilities.
- 7B+ models internalize large scale robotic pretraining so that a few thousand post training steps on downstream tasks are sufficient for transfer.
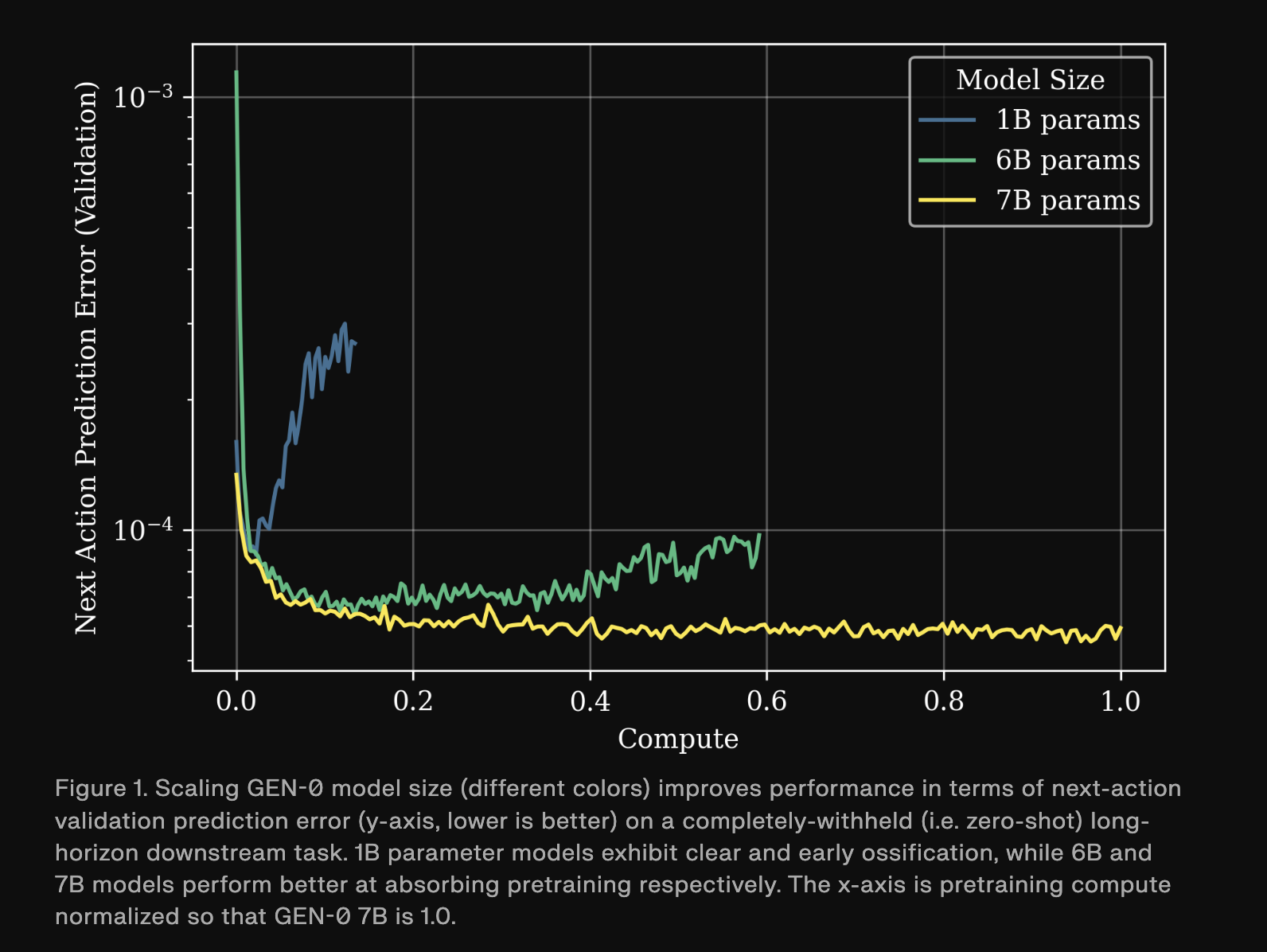
The above image plots next action validation prediction error on a completely withheld long horizon downstream task across model sizes and pre-training compute. 1B models plateau early while 6B and 7B models continue to improve as pretraining increases. The research team connect this phase transition to Moravec’s Paradox, arguing that physical commonsense and dexterity appear to require higher compute thresholds than abstract language reasoning, and that GEN-θ is operating beyond that activation point.
Generalist AI team states that GEN-θ has been scaled to 10B+ model sizes, and that larger variants adapt to new tasks with increasingly less post training.
Scaling laws for robotics
Another focus of this research is scaling laws that relate pre-training data and compute to downstream post training performance. The research team samples checkpoints from GEN-θ training runs on different subsets of the pre-training dataset, then post trains those checkpoints on multi task, language conditioned data. This supervised fine tuning stage spans 16 task sets, covering dexterity tasks such as building Lego, industry workflows such as fast food packing, and generalization tasks that include anything style instructions.
Across various tasks, more pre-training improves validation loss and next action prediction error during post training. At sufficient model scale, the relationship between pre-training dataset size and downstream validation error is well described by a power law of the form.
L(D)=(Dc/D)αD
where (D) is the number of action trajectories in pre-training and (L(D)) is validation error on a downstream task. This formula lets robotics teams estimate how much pre-training data is needed to reach a target next action prediction error, or how much downstream labeled data can be traded for additional pre-training.
Data engine and infrastructure at robotics scale
GEN-θ is trained on an in house dataset of 270,000 hours of real world manipulation trajectories collected in thousands of homes, warehouses and workplaces worldwide. The data operation currently adds more than 10,000 new hours per week. Generalist AI team claims that GEN-θ is trained on orders of magnitude more real world manipulation data than prior large robotics datasets as of today.
To sustain this regime, the research team has built custom hardware, data-loaders and network infrastructure, including dedicated internet lines to handle uplink bandwidth from distributed sites. The pipeline uses multi cloud contracts, custom upload machines and on the order of 10,000 compute cores for continual multimodal processing. The research team reports compression of dozens of petabytes of data and data-loading techniques from frontier video foundation models, yielding a system capable of absorbing 6.85 years of real world manipulation experience per day of training.
How you pre-train GEN-θ matters as much as how big it is?
Generalist AI team runs large ablations over 8 pre-training datasets and 10 long horizon task sets. They find that different data mixtures, not just more data, produce models with different behaviors across 3 groups of tasks, dexterity, real world applications and generalization. Performance is measured using validation mean squared error on next actions and reverse Kullback Leibler divergence between the model policy and a Gaussian around ground truth actions.
Low MSE and low reverse KL models are better candidates for supervised fine-tuning. Models with higher MSE but low reverse KL are more multimodal in their action distributions and can be better starting points for reinforcement learning.
Key Takeaways
- GEN-θ is an embodied foundation model trained on high fidelity raw physical interaction data, not simulation or internet video, and it uses Harmonic Reasoning to think and act simultaneously under real world physics.
- Scaling experiments show an intelligence threshold around 7B parameters, where smaller models ossify under high data load and larger models keep improving with more pretraining.
- GEN-θ exhibits clear scaling laws, where downstream post training performance follows a power law in the amount of pre-training data, which lets teams predict how much data and compute are needed for target error levels.
- The system is trained on more than 270,000 hours of real world manipulation data, growing by about 10,000 hours per week, supported by custom multi cloud infrastructure that can absorb 6.85 years of experience per training day.
- Large scale ablations over 8 pretraining datasets and 10 long horizon task sets show that data quality and mixture design, measured with validation MSE and reverse KL, are as important as scale, since different mixtures yield models better suited for supervised finetuning or reinforcement learning.
GEN-θ positions embodied foundation models as a serious attempt to bring scaling laws to robotics, using Harmonic Reasoning, large scale multimodal pre-training and explicit analysis of data mixtures. The research shows that 7B+ models, trained on 270,000 hours of real world manipulation data with 10,000 hours added weekly, can cross an intelligence threshold where more physical interaction data predictably improves downstream performance across dexterity, applications and generalization tasks.
Check out the Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.