Can We Improve Llama 3’s Reasoning Through Post-Training Alone? ASTRO Shows +16% to +20% Benchmark Gains
Improving the reasoning capabilities of large language models (LLMs) without architectural changes is a core challenge in advancing AI alignment and usability. Researchers at Meta AI and the University of Washington have introduced ASTRO—Autoregressive Search-Taught Reasoner—a novel post-training framework designed to enhance reasoning in Llama-3.1-70B-Instruct. ASTRO is unique in teaching models to perform in-context search, self-reflection, and backtracking, mechanisms often associated with human problem-solving and traditional symbolic search algorithms. Through this approach, ASTRO boosts Llama 3’s math performance on several competitive benchmarks with significant improvements:
- MATH 500: 65.8% ➝ 81.8%
- AMC 2023: 37.5% ➝ 64.4%
- AIME 2024: 10.0% ➝ 30.0%
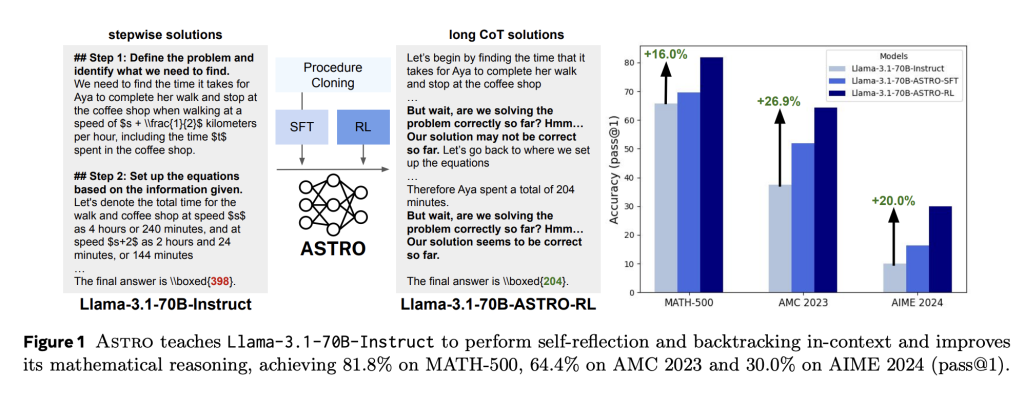
Search-Guided Chain-of-Thought Generation
ASTRO’s methodology begins with a Monte Carlo Tree Search (MCTS) over mathematical problem-solving trajectories. This search explores both correct and incorrect reasoning paths. The key innovation is procedure cloning: entire search trees are linearized into long chain-of-thoughts (CoT) that naturally encode both failures and recoveries via self-reflection and backtracking. These linearized traces are rewritten in natural language and used as the basis for supervised fine-tuning (SFT).
This results in a model that doesn’t just solve problems step-by-step but reevaluates its trajectory—often backtracking after self-assessment to correct intermediate reasoning mistakes. For instance, the model may interject with phrases like “Let’s go back to where we set up the equation” when its internal confidence drops.
Supervised Fine-Tuning: Injecting Search Priors
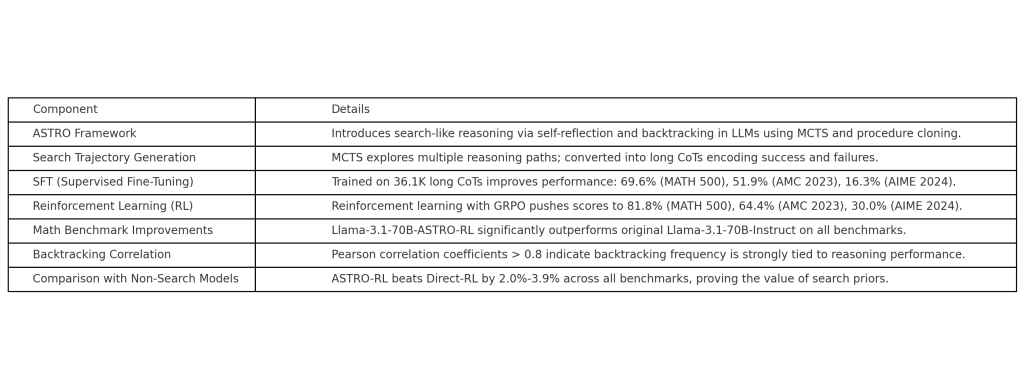
ASTRO fine-tunes Llama-3.1-70B-Instruct on 36.1K curated CoT solutions from MATH, AMC/AIME, and AoPS-style datasets. The model trained with ASTRO-SFT achieves:
- MATH 500: 69.6%
- AMC 2023: 51.9%
- AIME 2024: 16.3%
These scores are competitive with or exceed those of baseline and SPOC/Step-KTO variants trained without explicit search priors. Importantly, even SFT alone—without reinforcement learning—yields performance boosts by exposing the model to search-structured reasoning data.
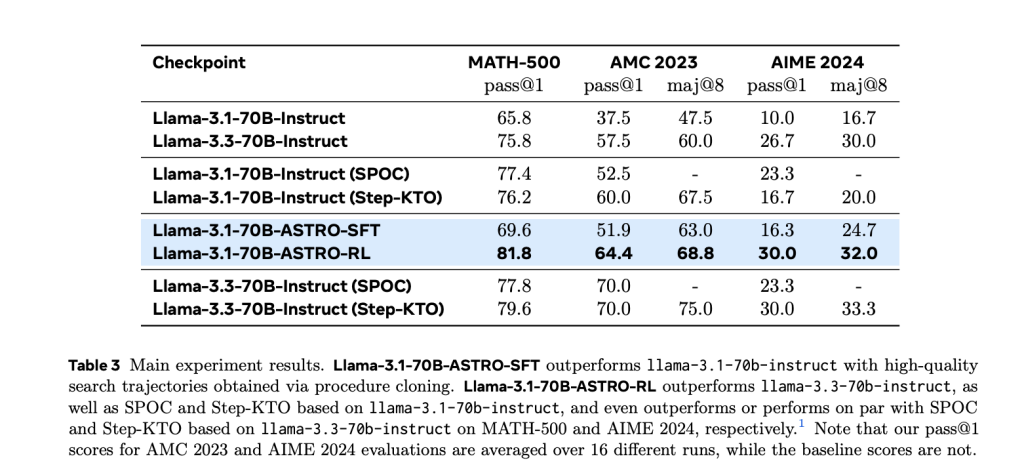
Reinforcement Learning with Search-Aware Initialization
ASTRO proceeds to reinforcement learning (RL) by initializing with the SFT checkpoint and running an RL loop using a modified Group Relative Policy Optimization (GRPO). Unlike standard preference-based RL, ASTRO employs verifiable reward signals (+1 for correct, -1 for incorrect) on 8.7K moderately difficult prompts. During training, the model’s CoT generation grows longer—from ~1.8K to ~6K tokens—demonstrating deeper internal exploration.
The resulting ASTRO-RL model achieves:
- MATH 500: 81.8%
- AMC 2023: 64.4%
- AIME 2024: 30.0%
These results rival or exceed models with larger parameter counts and confirm the importance of ASTRO’s search-aware initialization.
Backtracking Behavior Correlates with Reasoning Success
A striking empirical observation is the positive correlation between backtracking frequency and performance. As training progresses, ASTRO-RL exhibits more self-corrective actions and deeper exploration. Pearson correlation coefficients across benchmarks exceed 0.8, indicating that self-reflection and backtracking are not merely cosmetic behaviors but functionally tied to better accuracy.
Comparative Insights and Broader Impact
Control experiments comparing ASTRO with models trained on direct CoT solutions (no search priors) reveal that even when trained on the same problem sets and search trees, ASTRO consistently outperforms. For instance, ASTRO-RL beats Direct-RL by:
- +2% on MATH 500
- +3.9% on AMC 2023
- +2.9% on AIME 2024
Moreover, ASTRO’s outputs can be visualized as directed graphs, with nodes as reasoning steps and edges capturing transitions, reflections, and corrections—facilitating better interpretability.
ASTRO Key Takeaways Table
Conclusion
ASTRO demonstrates that LLMs like Llama 3 can learn to reason more effectively—not through larger models or longer pretraining, but via principled post-training techniques. By mimicking search algorithms in natural language, ASTRO enables models to think before answering, doubt their own steps, and correct themselves mid-reasoning. This framework sets a new benchmark for fine-tuning open LLMs to approach human-like reasoning through search-inspired behaviors.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.
