Why Spatial Supersensing is Emerging as the Core Capability for Multimodal AI Systems?
Even strong ‘long-context’ AI models fail badly when they must track objects and counts over long, messy video streams, so the next competitive edge will come from models that predict what comes next and selectively remember only surprising, important events, not from just buying more compute and bigger context windows. A team of researchers from New York University and Stanford introduce Cambrian-S, a spatially grounded video multimodal large language model family, together with the VSI Super benchmark and the VSI 590K dataset to test and train spatial supersensing in long videos.
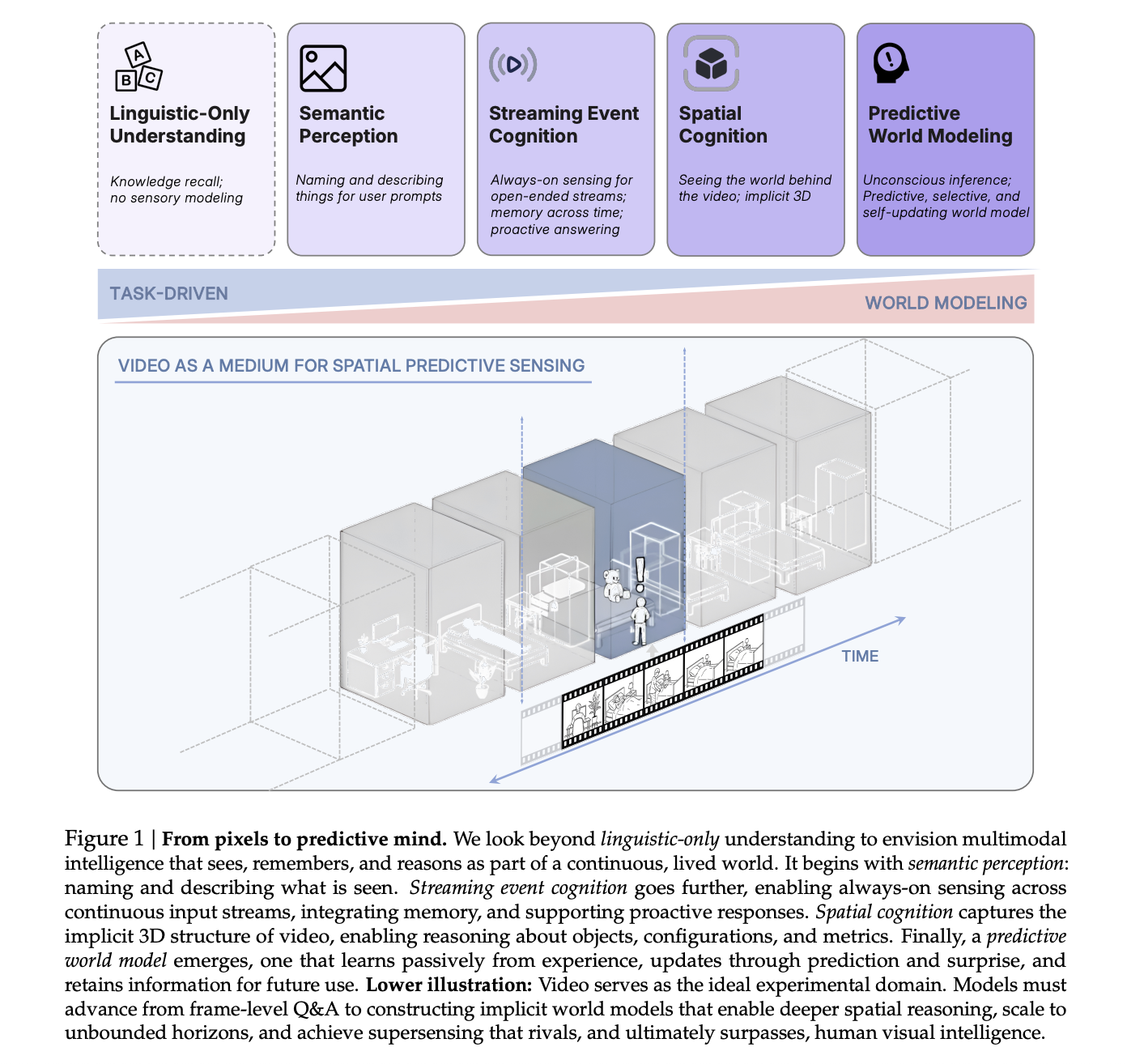
From video question answering to spatial supersensing
The research team frames spatial supersensing as a progression of capabilities beyond linguistic only reasoning. The stages are semantic perception, streaming event cognition, implicit 3D spatial cognition and predictive world modeling.
Most current video MLLMs sample sparse frames and rely on language priors. They often answer benchmark questions using captions or single frames rather than continuous visual evidence. Diagnostic tests show that several popular video benchmarks are solvable with limited or text only input, so they do not strongly test spatial sensing.
Cambrian-S targets the higher stages of this hierarchy, where the model must remember spatial layouts across time, reason about object locations and counts and anticipate changes in a 3D world.
VSI Super, a stress test for continual spatial sensing
To expose the gap between current systems and spatial supersensing, the research team designed VSI Super, a two part benchmark that runs on arbitrarily long indoor videos.

VSI Super Recall, or VSR, evaluates long horizon spatial observation and recall. Human annotators take indoor walkthrough videos from ScanNet, ScanNet++ and ARKitScenes and use Gemini to insert an unusual object, such as a Teddy Bear, into four frames at different spatial locations. These edited sequences are concatenated into streams up to 240 minutes. The model must report the order of locations where the object appears, which is a visual needle in a haystack task with sequential recall.

VSI Super Count, or VSC, measures continual counting under changing viewpoints and rooms. The benchmark concatenates room tour clips from VSI Bench and asks for the total number of instances of a target object across all rooms. The model must handle viewpoint changes, revisits and scene transitions and maintain a cumulative count. Evaluation uses mean relative accuracy for durations from 10 to 120 minutes.
When Cambrian-S 7B is evaluated on VSI Super in a streaming setup at 1 frame per second, accuracy on VSR drops from 38.3 percent at 10 minutes to 6.0 percent at 60 minutes and becomes zero beyond 60 minutes. VSC accuracy is near zero across lengths. Gemini 2.5 Flash also degrades on VSI Super despite a long context window, which shows that brute force context scaling is not sufficient for continual spatial sensing.
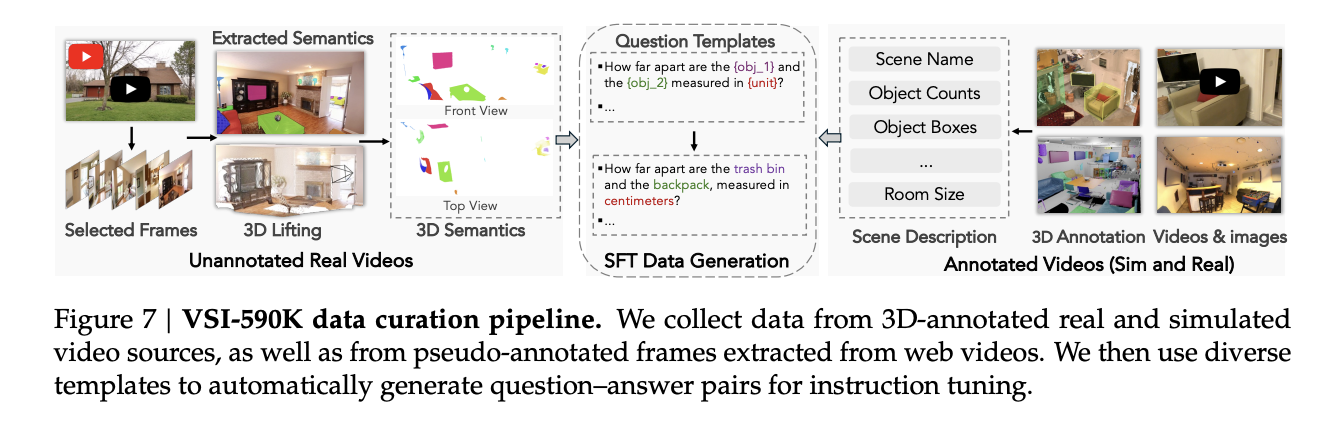
VSI 590K, spatially focused instruction data
To test whether data scaling can help, the research team construct VSI 590K, a spatial instruction corpus with 5,963 videos, 44,858 images and 590,667 question answer pairs from 10 sources.
Sources include 3D annotated real indoor scans such as ScanNet, ScanNet++ V2, ARKitScenes, S3DIS and Aria Digital Twin, simulated scenes from ProcTHOR and Hypersim and pseudo annotated web data such as YouTube RoomTour and robot datasets Open X Embodiment and AgiBot World.
The dataset defines 12 spatial question types, such as object count, absolute and relative distance, object size, room size and appearance order. Questions are generated from 3D annotations or reconstructions so that spatial relationships are grounded in geometry rather than text heuristics. Ablations show that annotated real videos contribute the largest gains on VSI Bench, followed by simulated data and then pseudo annotated images and that training on the full mix gives the best spatial performance.
Cambrian-S model family and spatial performance
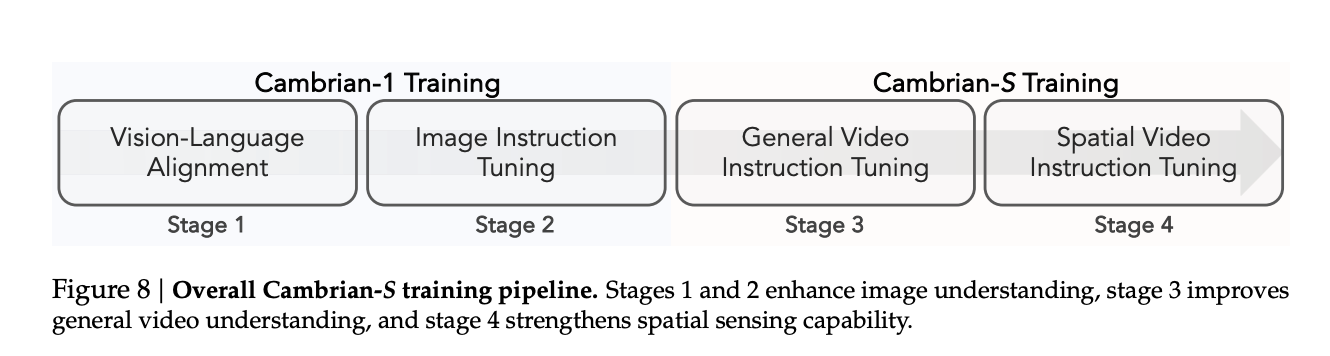
Cambrian-S builds on Cambrian-1 and uses Qwen2.5 language backbones at 0.5B, 1.5B, 3B and 7B parameters with a SigLIP2 SO400M vision encoder and a two layer MLP connector.
Training follows a four stage pipeline. Stage 1 performs vision language alignment on image text pairs. Stage 2 applies image instruction tuning, equivalent to the improved Cambrian-1 setup. Stage 3 extends to video with general video instruction tuning on a 3 million sample mixture called Cambrian-S 3M. Stage 4 performs spatial video instruction tuning on a mixture of VSI 590K and a subset of the stage 3 data.
On VSI Bench, Cambrian-S 7B reaches 67.5 percent accuracy and outperforms open source baselines like InternVL3.5 8B and Qwen VL 2.5 7B as well as proprietary Gemini 2.5 Pro by more than 16 absolute points. The model also maintains strong performance on Perception Test, EgoSchema and other general video benchmarks, so the focus on spatial sensing does not destroy general capabilities.
Predictive sensing with latent frame prediction and surprise
To go beyond static context expansion, the research team propose predictive sensing. They add a Latent Frame Prediction head, which is a two layer MLP that predicts the latent representation of the next video frame in parallel with next token prediction.
Training modifies stage 4. The model uses mean squared error and cosine distance losses between predicted and ground truth latent features, weighted against the language modeling loss. A subset of 290,000 videos from VSI 590K, sampled at 1 frame per second, is reserved for this objective. During this stage the connector, language model and both output heads are trained jointly, while the SigLIP vision encoder remains frozen.
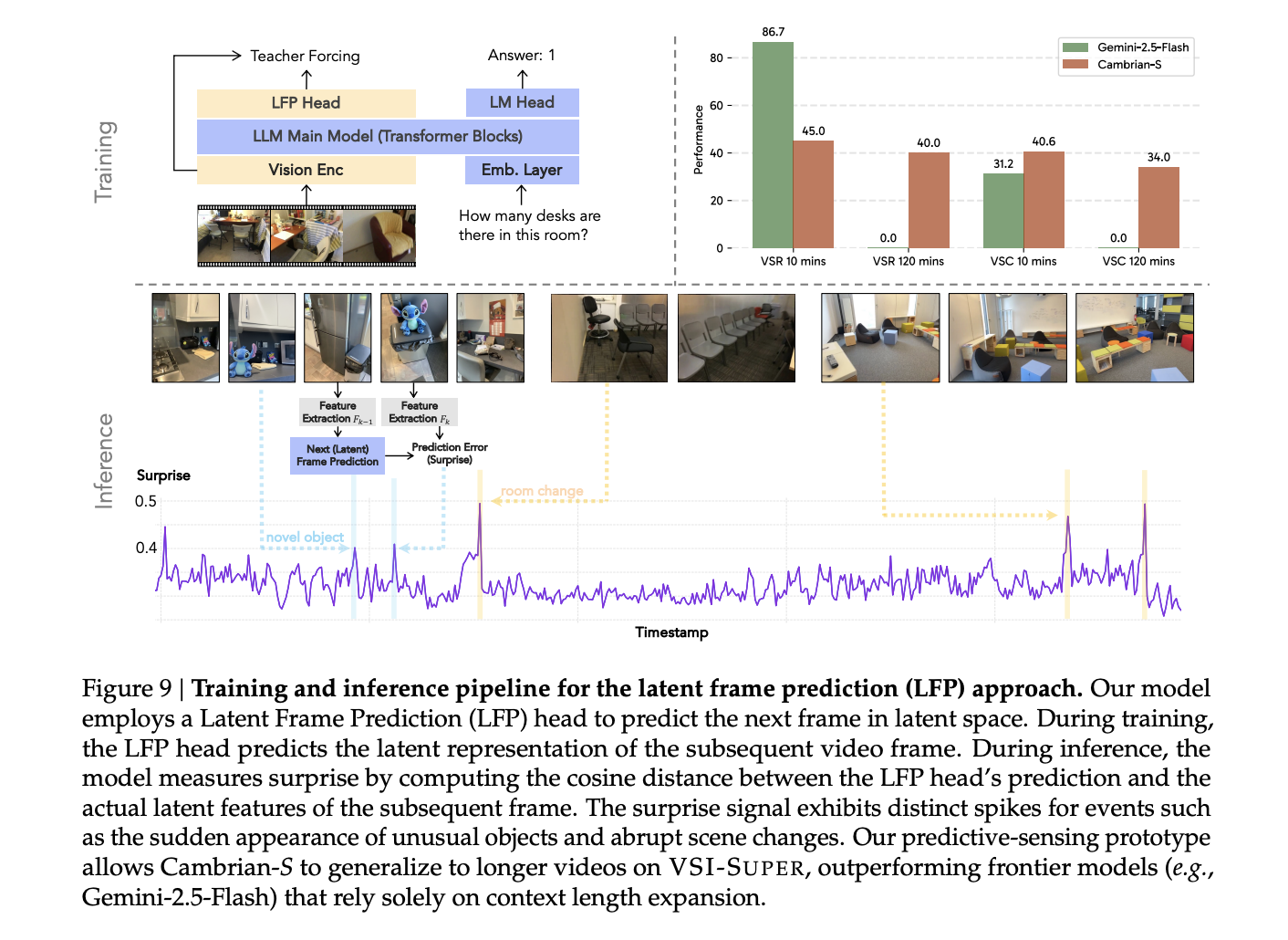
At inference time the cosine distance between predicted and actual features becomes a surprise score. Frames with low surprise are compressed before being stored in long term memory and high surprise frames are retained with more detail. A fixed size memory buffer uses surprise to decide which frames to consolidate or drop and queries retrieve frames that are most relevant to the question.
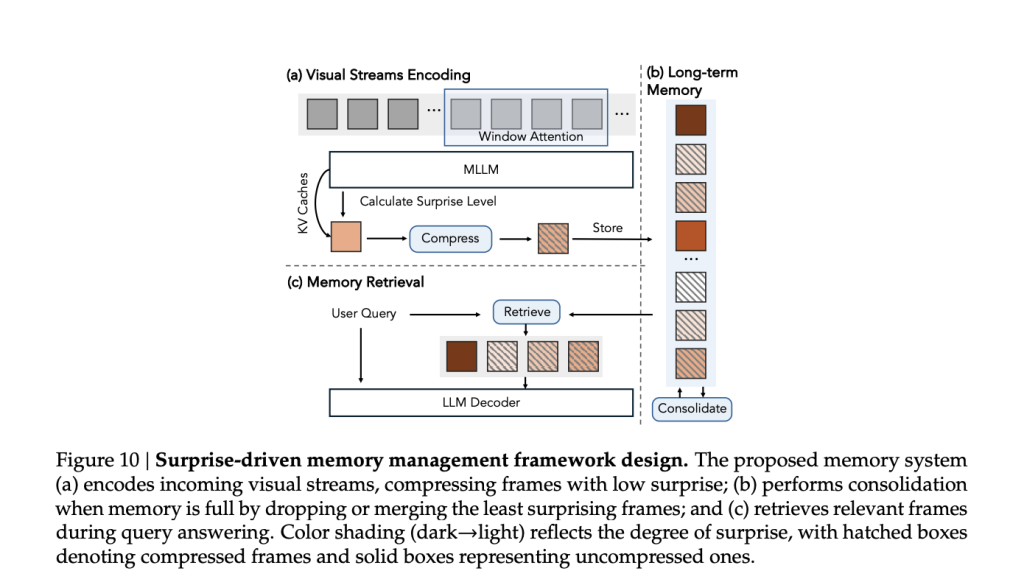
For VSR, this surprise driven memory system lets Cambrian-S maintain accuracy as video length increases while keeping GPU memory usage stable. It outperforms Gemini 1.5 Flash and Gemini 2.5 Flash on VSR at all tested durations and avoids the sharp degradation seen in models that only extend context.
For VSC, the research team designed a surprise driven event segmentation scheme. The model accumulates features in an event buffer and when a high surprise frame signals a scene change, it summarizes that buffer into a segment level answer and resets the buffer. Aggregating segment answers gives the final count. In streaming evaluation, Gemini Live and GPT Realtime achieve less than 15 percent mean relative accuracy and drop near zero on 120 minute streams, while Cambrian-S with surprise segmentation reaches about 38 percent at 10 minutes and maintains around 28 percent at 120 minutes.
Key Takeaways
- Cambrian-S and VSI 590K show that careful spatial data design and strong video MLLMs can significantly improve spatial cognition on VSI Bench, but they still fail on VSI Super, so scale alone does not solve spatial supersensing.
- VSI Super, through VSR and VSC, is intentionally built from arbitrarily long indoor videos to stress continual spatial observation, recall and counting, which makes it resistant to brute force context window expansion and standard sparse frame sampling.
- Benchmarking shows that frontier models, including Gemini 2.5 Flash and Cambrian S, degrade sharply on VSI Super even when video lengths remain within their nominal context limits, revealing a structural weakness in current long context multimodal architectures.
- The Latent Frame Prediction based predictive sensing module uses next latent frame prediction error, or surprise, to drive memory compression and event segmentation, which yields substantial gains on VSI Super compared to long context baselines while keeping GPU memory usage stable.
- The research work positions spatial supersensing as a hierarchy from semantic perception to predictive world modeling and argues that future video MLLMs must incorporate explicit predictive objectives and surprise driven memory, not only larger models and datasets, to handle unbounded streaming video in real applications.
Cambrian-S is a useful stress test of current video MLLMs because it shows that VSI SUPER is not just a harder benchmark, it exposes a structural failure of long context architectures that still rely on reactive perception. The predictive sensing module, based on Latent Frame Prediction and surprise driven memory, is an important step because it couples spatial sensing with internal world modeling rather than only scaling data and parameters. This research signals a shift from passive video understanding to predictive spatial supersensing as the next design target for multimodal models.
Check out the Paper. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.