Meta AI Introduces DeepConf: First AI Method to Achieve 99.9% on AIME 2025 with Open-Source Models Using GPT-OSS-120B
Large language models (LLMs) have reshaped AI reasoning, with parallel thinking and self-consistency methods often cited as pivotal advances. However, these techniques face a fundamental trade-off: sampling multiple reasoning paths boosts accuracy but at a steep computational cost. A team of researchers from Meta AI and UCSD introduce Deep Think with Confidence (DeepConf), a new AI approachthat nearly eliminates this trade-off. DeepConf delivers state-of-the-art reasoning performance with dramatic efficiency gains—achieving, for example, 99.9% accuracy on the grueling AIME 2025 math competition using the open-source GPT-OSS-120B, while requiring up to 85% fewer generated tokens than conventional parallel thinking approaches.
Why DeepConf?
Parallel thinking (self-consistency with majority voting) is the de facto standard for boosting LLM reasoning: generate multiple candidate solutions, then pick the most common answer. While effective, this method has diminishing returns—accuracy plateaus or even declines as more paths are sampled, because low-quality reasoning traces can dilute the vote. Moreover, generating hundreds or thousands of traces per query is costly, both in time and compute.
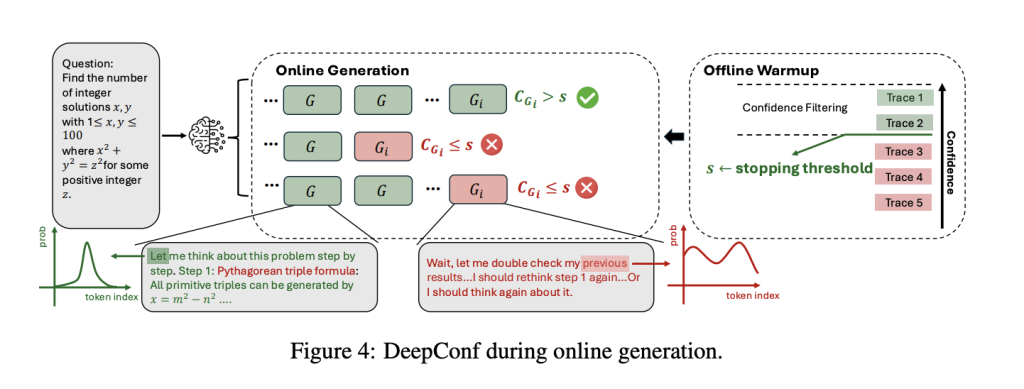
DeepConf tackles these challenges by exploiting the LLM’s own confidence signals. Rather than treating all reasoning traces equally, it dynamically filters out low-confidence paths—either during generation (online) or afterward (offline)—using only the most reliable trajectories to inform the final answer. This strategy is model-agnostic, requires no training or hyperparameter tuning, and can be plugged into any existing model or serving framework with minimal code changes.
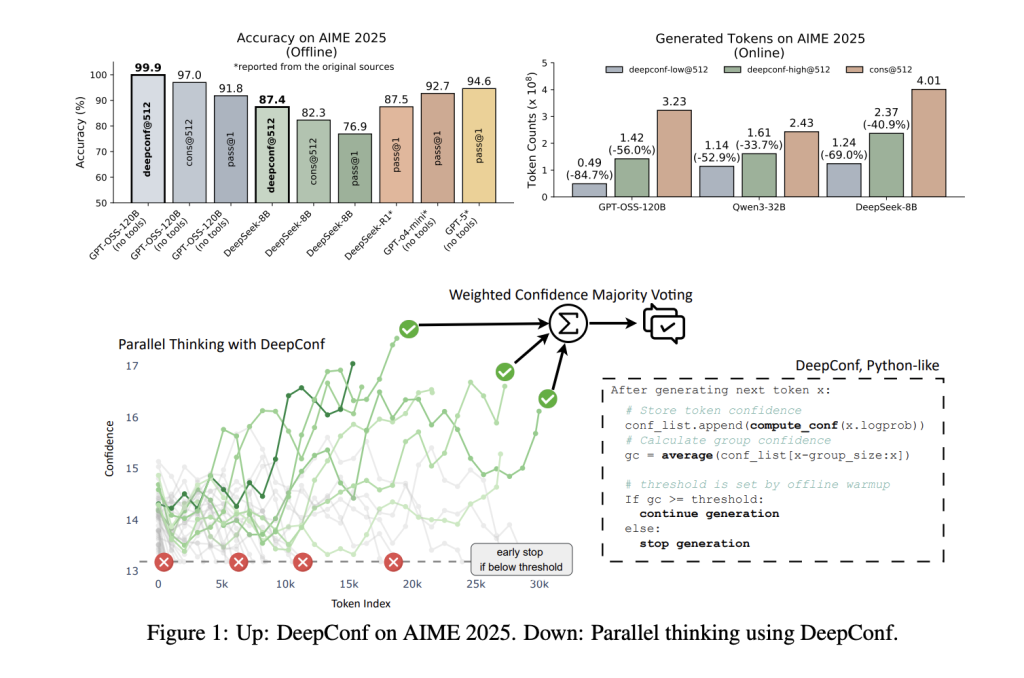
How DeepConf Works: Confidence as a Guide
DeepConf introduces several advancements in how confidence is measured and used:
- Token Confidence: For each generated token, compute the negative average log-probability of the top-k candidates. This gives a local measure of certainty.
- Group Confidence: Average token confidence over a sliding window (e.g., 2048 tokens), providing a smoothed, intermediate signal of reasoning quality.
- Tail Confidence: Focus on the final segment of the reasoning trace, where the answer often resides, to catch late breakdowns.
- Lowest Group Confidence: Identify the least confident segment in the trace, which often signals reasoning collapse.
- Bottom Percentile Confidence: Highlight the worst segments, which are most predictive of errors.
These metrics are then used to weight votes (high-confidence traces count more) or to filter traces (only the top η% most confident traces are kept). In online mode, DeepConf stops generating a trace as soon as its confidence drops below a dynamically calibrated threshold, dramatically reducing wasted computation.
Key Results: Performance & Efficiency
DeepConf was evaluated across multiple reasoning benchmarks (AIME 2024/2025, HMMT 2025, BRUMO25, GPQA-Diamond) and models (DeepSeek-8B, Qwen3-8B/32B, GPT-OSS-20B/120B). The results are striking:
| Model | Dataset | Pass@1 Acc | Cons@512 Acc | DeepConf@512 Acc | Tokens Saved |
|---|---|---|---|---|---|
| GPT-OSS-120B | AIME 2025 | 91.8% | 97.0% | 99.9% | -84.7% |
| DeepSeek-8B | AIME 2024 | 83.0% | 86.7% | 93.3% | -77.9% |
| Qwen3-32B | AIME 2024 | 80.6% | 85.3% | 90.8% | -56.0% |
Performance boost: Across models and datasets, DeepConf improves accuracy by up to ~10 percentage points over standard majority voting, often saturating the benchmark’s upper limit.
Ultra-efficient: By early-stopping low-confidence traces, DeepConf reduces the total number of generated tokens by 43–85%, with no loss (and often a gain) in final accuracy.
Plug & play: DeepConf works out of the box with any model—no fine-tuning, no hyperparameter search, and no changes to the underlying architecture. You can drop it into your existing serving stack (e.g., vLLM) with ~50 lines of code.
Easy to deploy: The method is implemented as a lightweight extension to existing inference engines, requiring only access to token-level logprobs and a few lines of logic for confidence calculation and early stopping.
Simple Integration: Minimal Code, Maximum Impact
DeepConf’s implementation is quite simple. For vLLM, the changes are minimal:
- Extend the logprobs processor to track sliding-window confidence.
- Add an early-stop check before emitting each output.
- Pass confidence thresholds via the API, with no model retraining.
This allows any OpenAI-compatible endpoint to support DeepConf with a single extra setting, making it trivial to adopt in production environments.
Conclusion
Meta AI’s DeepConf represents a leap forward in LLM reasoning, delivering both peak accuracy and unprecedented efficiency. By dynamically leveraging the model’s internal confidence, DeepConf achieves what was previously out of reach for open-source models: near-perfect results on elite reasoning tasks, with a fraction of the computational cost.
FAQs
FAQ 1: How does DeepConf improve accuracy and efficiency compared to majority voting?
DeepConf’s confidence-aware filtering and voting prioritizes traces with higher model certainty, boosting accuracy by up to 10 percentage points across reasoning benchmarks compared to majority voting alone. At the same time, its early termination of low-confidence traces slashes token usage by up to 85%, offering both performance and massive efficiency gains in practical deployments
FAQ 2: Can DeepConf be used with any language model or serving framework?
Yes. DeepConf is fully model-agnostic and can be integrated into any serving stack—including open-source and commercial models—without modification or retraining. Deployment requires only minimal changes (~50 lines of code for vLLM), leveraging token logprobs to compute confidence and handle early stopping.
FAQ 2: Does DeepConf require retraining, special data, or complex tuning?
No. DeepConf operates entirely at inference-time, requiring no additional model training, fine-tuning, or hyperparameter searches. It uses only built-in logprob outputs and works immediately with standard API settings for leading frameworks; it’s scalable, robust, and deployable on real workloads without interruption.
Check out the Paper and Project Page. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.