Alberto
Alberto
septembre 17, 2025
VALORANT provides key details surrounding replay system
Crypto News
Alberto
septembre 17, 2025
Solana (SOL) Holds Recent Gains – Key Levels Before Another Surge
Blockchain
Alberto
septembre 17, 2025
Tom Lee Sees « Monster » Gains For BTC, ETH On Fed Rate Cut
Bitcoin
Alberto
septembre 17, 2025
Fed Third Mandate Could Boost Crypto As Dollar Weakens
Ethereum
Alberto
septembre 17, 2025
No New All-Time High Expected, Year-End Target At $4,300
eSports
Alberto
septembre 17, 2025
Borderlands 4: Nvidia lists optimal settings for 18 graphics cards, sparking debate
Ai
Alberto
septembre 17, 2025
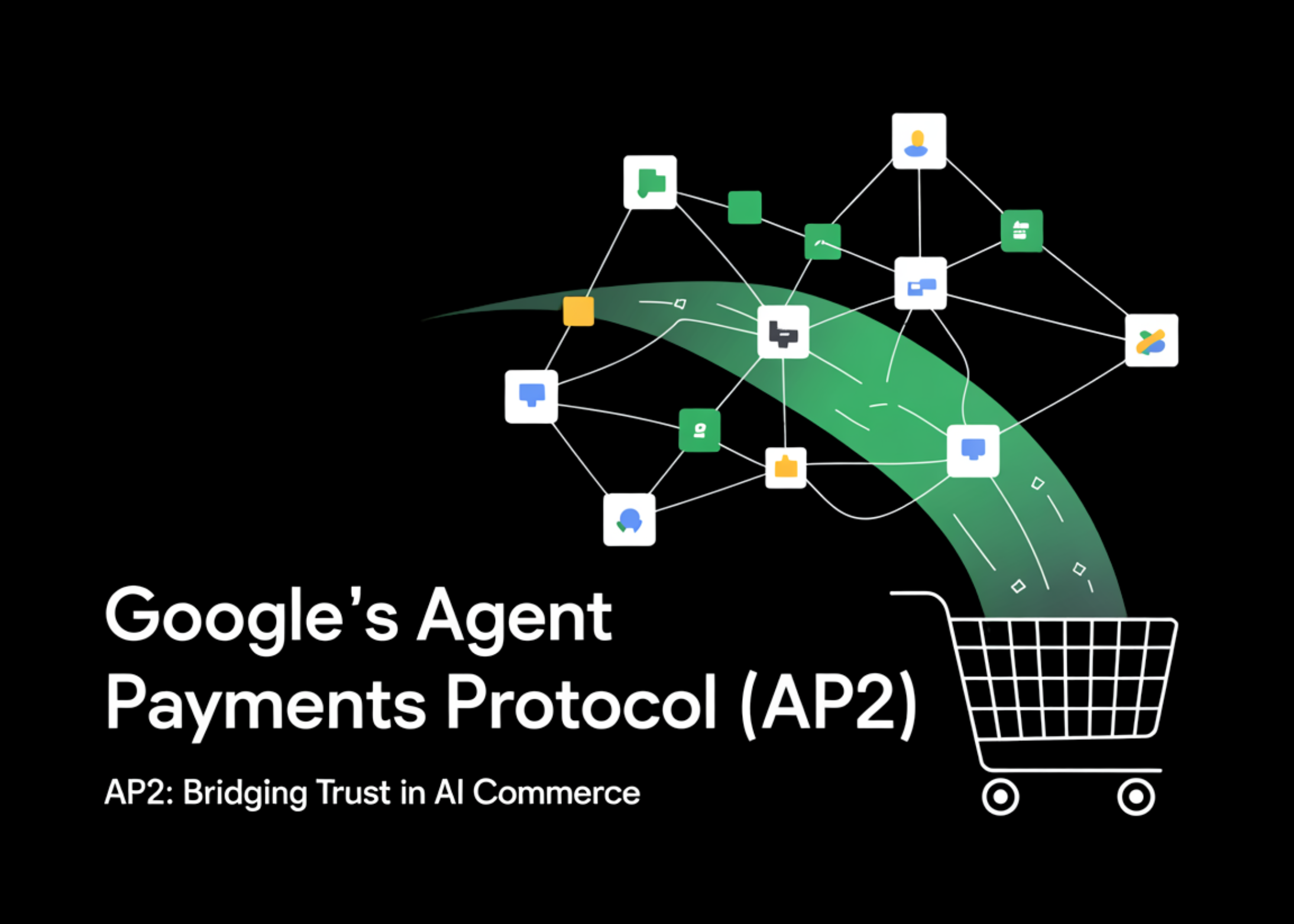
Google AI Introduces Agent Payments Protocol (AP2): An Open Protocol for Interoperable AI Agent Checkout Across Merchants and Wallets
Crypto News
Alberto
septembre 17, 2025
Fed Third Mandate Could Boost Crypto As Dollar Weakens
eSports
Alberto
septembre 17, 2025
GamerLegion Announces the Benching of Kursy, Signs hypex to Replace Him
Crypto News
Alberto
septembre 17, 2025
Bitmine Chairman Predicts Sharp Crypto Rally on Fed Rate Cuts
Page précédente
Page suivante