Alibaba Qwen Team Releases Mobile-Agent-v3 and GUI-Owl: Next-Generation Multi-Agent Framework for GUI Automation
Introduction: The Rise of GUI Agents
Modern computing is dominated by graphical user interfaces across devices—mobile, desktop, and web. Automating tasks in these environments has traditionally been limited to scripted macros or brittle, hand-engineered rules. Recent advances in vision-language models offer the tantalizing possibility of agents that can understand screens, reason about tasks, and execute actions just like humans. However, most approaches have either relied on closed-source, black-box models or have struggled with generalizability, reasoning fidelity, and cross-platform robustness.
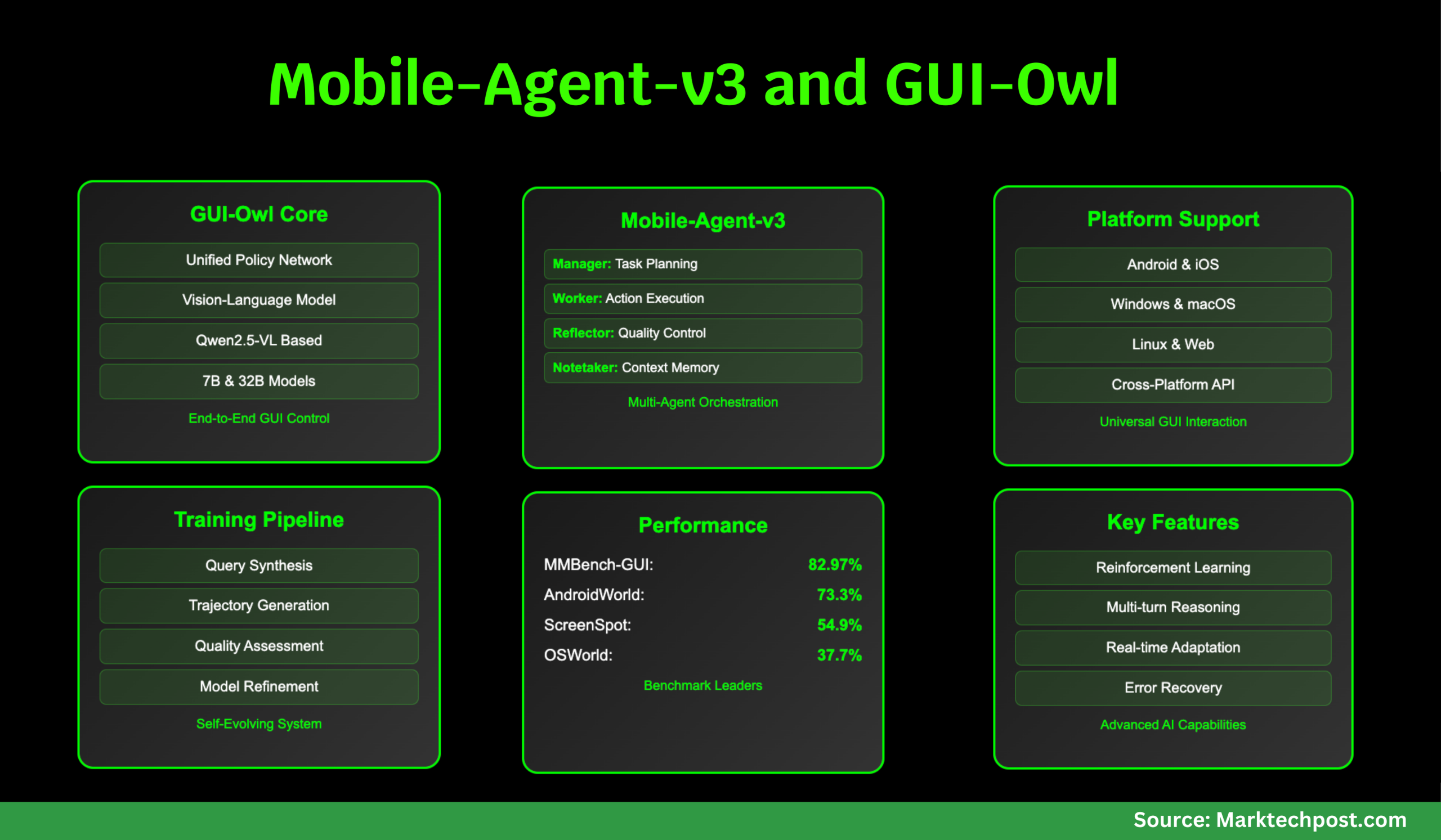
A team of researchers from Alibaba Qwen introduce GUI-Owl and Mobile-Agent-v3 that these challenges head-on. GUI-Owl is a native, end-to-end multimodal agent model, built on Qwen2.5-VL and extensively post-trained on large-scale, diverse GUI interaction data. It unifies perception, grounding, reasoning, planning, and action execution within a single policy network, enabling robust cross-platform interaction and explicit multi-turn reasoning. The Mobile-Agent-v3 framework leverages GUI-Owl as a foundational module, orchestrating multiple specialized agents (Manager, Worker, Reflector, Notetaker) to handle complex, long-horizon tasks with dynamic planning, reflection, and memory.
Architecture and Core Capabilities
GUI-Owl: The Foundational Model
GUI-Owl is designed from the ground up to handle the heterogeneity and dynamism of real-world GUI environments. It is initialized from Qwen2.5-VL, a state-of-the-art vision-language model, but undergoes extensive additional training on specialized GUI datasets. This includes grounding (locating UI elements from natural language queries), task planning (breaking down complex instructions into actionable steps), and action semantics (understanding how actions affect the GUI state). The model is fine-tuned via a mix of supervised learning and reinforcement learning (RL), with a focus on aligning its decisions with real-world task success.
Key Innovations in GUI-Owl:
- Unified Policy Network: Unlike prior research that separates perception, planning, and execution into disjoint modules, GUI-Owl integrates these capabilities into a single neural network. This allows for seamless multi-turn decision-making and explicit intermediate reasoning—crucial for handling the ambiguity and variability of real GUIs.
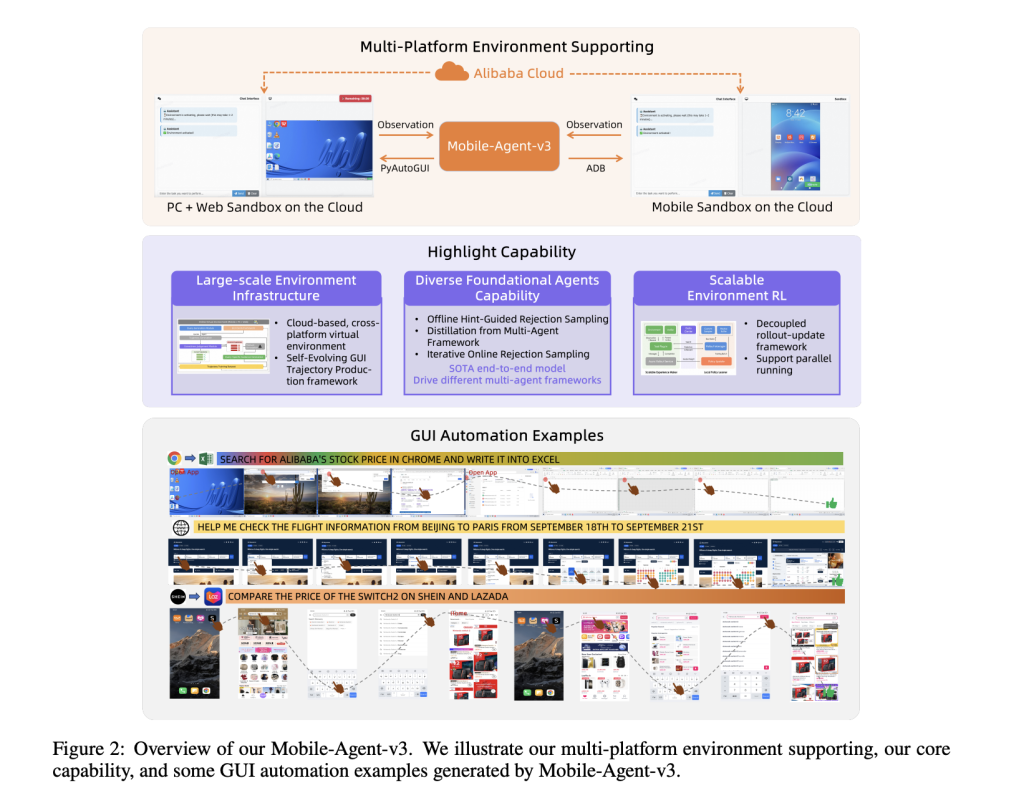
- Scalable Training Infrastructure: The team built a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows. This “Self-Evolving GUI Trajectory Production” pipeline generates high-quality interaction data by having GUI-Owl and Mobile-Agent-v3 interact with virtual devices, then rigorously judging the correctness of trajectories. Successful trajectories are used for further training, creating a virtuous cycle of improvement.
- Diverse Data Synthesis: To teach the model robust grounding and reasoning, the research team employ a variety of data synthesis strategies: synthesizing UI element grounding tasks from accessibility trees and crawled screenshots, distilling task planning knowledge from both historical trajectories and large pretrained LLMs, and generating action semantics data by having the model predict the effect of actions given before-and-after screenshots.
- Reinforcement Learning Alignment: GUI-Owl is further refined via a scalable RL framework that supports fully asynchronous training and a novel “Trajectory-aware Relative Policy Optimization” (TRPO). TRPO assigns credit across long, variable-length action sequences—a critical advance for GUI tasks where rewards are sparse and only available upon task completion.
Mobile-Agent-v3: Multi-Agent Coordination
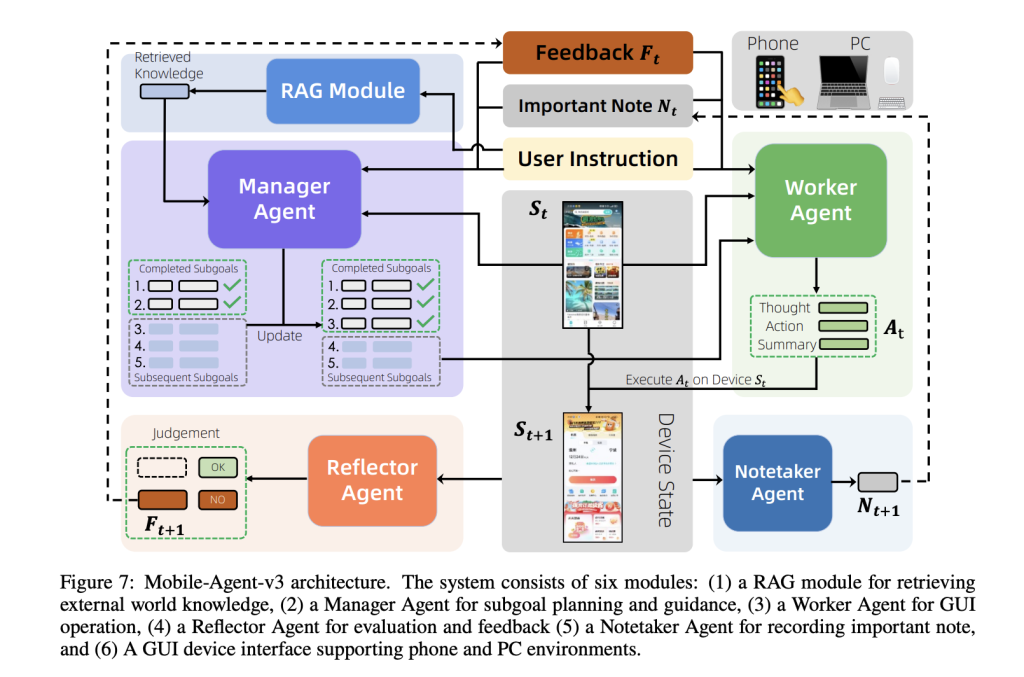
Mobile-Agent-v3 is a general-purpose agentic framework designed to tackle complex, multi-step, and cross-application workflows. It breaks tasks into subgoals, dynamically updates plans based on execution feedback, and maintains persistent contextual memory. The framework coordinates four specialized agents:
- Manager Agent: Decomposes high-level instructions into subgoals, dynamically updating the plan based on results and feedback.
- Worker Agent: Executes the most relevant actionable subgoal given the current GUI state, prior feedback, and accumulated notes.
- Reflector Agent: Evaluates the outcome of each action, comparing intended and actual state transitions to generate diagnostic feedback.
- Notetaker Agent: Persists critical information (e.g., codes, credentials) across application boundaries, enabling long-horizon tasks.
Training and Data Pipeline
A major bottleneck in GUI agent development is the lack of high-quality, scalable training data. Traditional approaches rely on expensive manual annotation, which does not scale to the diversity and dynamism of real GUIs. The GUI-Owl team addresses this with a self-evolving data production pipeline:
- Query Generation: For mobile apps, a human-annotated directed acyclic graph (DAG) models realistic navigation flows and slot-value pairs for user inputs. LLMs synthesize natural instructions from these paths, which are further refined and validated against real app interfaces.
- Trajectory Generation: Given a query, GUI-Owl or Mobile-Agent-v3 interacts with a virtual environment to produce a trajectory—a sequence of actions and state transitions.
- Trajectory Correctness Judgment: A two-level critic system evaluates each step (did the action have the intended effect?) and the overall trajectory (did the task succeed?). This uses both textual and multimodal reasoning, with consensus-based final judgments.
- Guidance Synthesis: For challenging queries, the system synthesizes step-by-step guidance from successful (human or model) trajectories, helping the agent learn from positive examples.
- Iterative Training: Newly generated successful trajectories are added to the training set, and the model is retrained, closing the loop on self-improvement.
Benchmarking and Performance
GUI-Owl and Mobile-Agent-v3 are rigorously evaluated across a suite of GUI automation benchmarks, covering grounding, single-step decision-making, question answering, and end-to-end task completion.
Grounding and UI Understanding
On grounding tasks—locating UI elements from natural language queries—GUI-Owl-7B outperforms all open-source models of comparable size, and GUI-Owl-32B surpasses even proprietary models like GPT-4o and Claude 3.7. For example, on the MMBench-GUI L2 benchmark (covering Windows, macOS, Linux, iOS, Android, and Web), GUI-Owl-7B scores 80.49, while GUI-Owl-32B achieves 82.97, both well ahead of the competition. On ScreenSpot Pro, which focuses on high-resolution, complex interfaces, GUI-Owl-7B scores 54.9, significantly outperforming UI-TARS-72B and Qwen2.5-VL-72B. These results demonstrate that GUI-Owl’s grounding capabilities are both broad and deep, handling everything from simple button clicks to fine-grained text localization.
Comprehensive GUI Understanding and Single-Step Decision Making
MMBench-GUI L1 evaluates UI understanding and single-step decision-making through question-answering. Here, GUI-Owl-7B scores 84.5 (easy), 86.9 (medium), and 90.9 (hard), far outpacing all existing models. This indicates not just accurate perception, but robust reasoning about interface states and actions. On Android Control, which focuses on single-step decisions in pre-annotated contexts, GUI-Owl-7B achieves 72.8, the highest among 7B models, while GUI-Owl-32B reaches 76.6, surpassing even the largest open and proprietary models.
End-to-End and Multi-Agent Capabilities
The real test of a GUI agent is its ability to complete real, multi-step tasks in interactive environments. AndroidWorld and OSWorld are two such benchmarks, where agents must autonomously navigate apps and operating systems to accomplish user instructions. GUI-Owl-7B scores 66.4 on AndroidWorld and 34.9 on OSWorld, while Mobile-Agent-v3 (with GUI-Owl as its core) achieves 73.3 and 37.7, respectively—a new state-of-the-art for open-source frameworks. The multi-agent design proves especially effective on long-horizon, error-prone tasks, as the Reflector and Manager agents enable dynamic replanning and recovery from mistakes.
Real-World Integration
The research team also evaluated GUI-Owl’s performance as the “brain” within established agentic frameworks like Mobile-Agent-E (Android) and Agent-S2 (desktop). Here, GUI-Owl-32B achieves 62.1% success on AndroidWorld and 48.4% on a challenging subset of OSWorld, significantly outperforming all baselines. This underscores GUI-Owl’s practical value as a plug-and-play module for diverse agent systems.
Real-World Deployment
GUI-Owl supports a rich, platform-specific action space. On mobile, this includes clicks, long presses, swipes, text entry, system buttons (back, home, etc.), and application launching. On desktop, actions encompass mouse moves, clicks, drags, scrolls, keyboard input, and application-specific commands. Actions are translated into low-level device commands (ADB for Android, pyautogui for desktop), making the framework readily deployable in real environments.
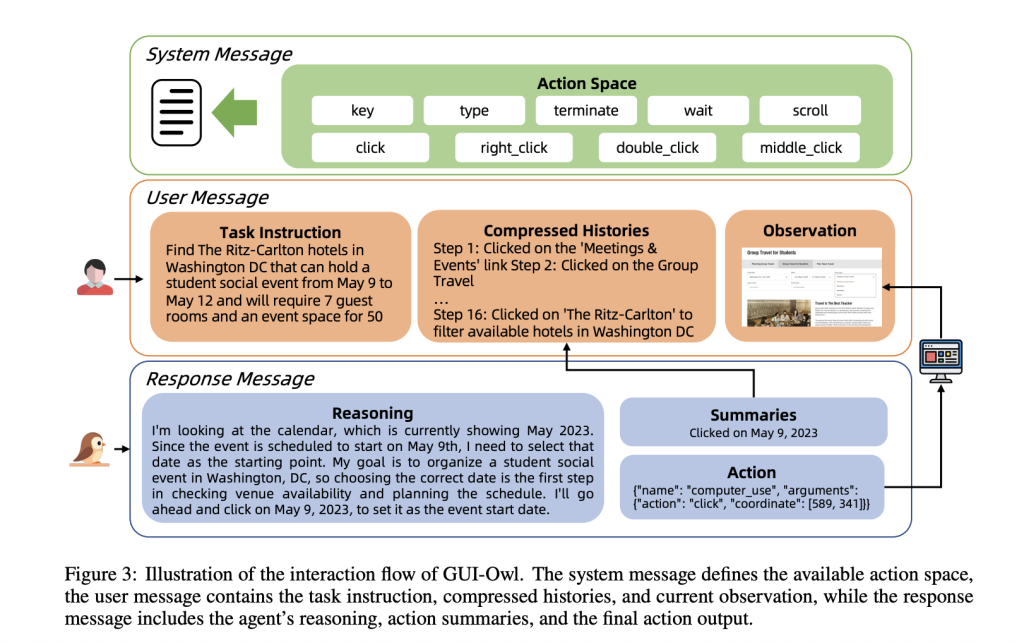
The agent’s reasoning and decision process is transparent: for each step, it observes the screen, recalls compressed history, reasons about the next action, summarizes its intent, and executes. This explicit intermediate reasoning not only improves robustness but also enables integration into larger multi-agent systems, where different “roles” (e.g., planner, executor, critic) can specialize and collaborate.
Conclusion: Toward General-Purpose GUI Agents
GUI-Owl and Mobile-Agent-v3 represent a major leap toward general-purpose, autonomous GUI agents. By unifying perception, grounding, reasoning, and action into a single model, and by building a scalable, self-improving training pipeline, the research team have achieved state-of-the-art performance across both mobile and desktop environments, surpassing even the largest proprietary models in key benchmarks.
Check out the PAPER and GITHUB PAGE. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.