Memory-R1: How Reinforcement Learning Supercharges LLM Memory Agents
Large language models (LLMs) now stand at the center of countless AI breakthroughs—chatbots, coding assistants, question answering, creative writing, and much more. But despite their prowess, they remain stateless: each query arrives with no memory of what came before. Their fixed context windows mean they can’t accumulate persistent knowledge across long conversations or multi-session tasks, and they struggle to reason over complex histories. Recent solutions, like retrieval-augmented generation (RAG), append past information to prompts, but this often leads to noisy, unfiltered context—flooding the model with too much irrelevant detail or missing crucial facts.
A team of researchers from University of Munich, Technical University of Munich, University of Cambridge and University of Hong Kong introduced Memory-R1, a framework that teaches LLM agents to decide what to remember and how to use it. Its LLM agent learns to actively manage and utilize external memory—deciding what to add, update, delete, or ignore, and filtering out noise when answering questions. The breakthrough? It trains these behaviors with reinforcement learning (RL), using only outcome-based rewards, so it needs minimal supervision and generalizes robustly across models and tasks.
But Why LLMs Struggle with Memory?
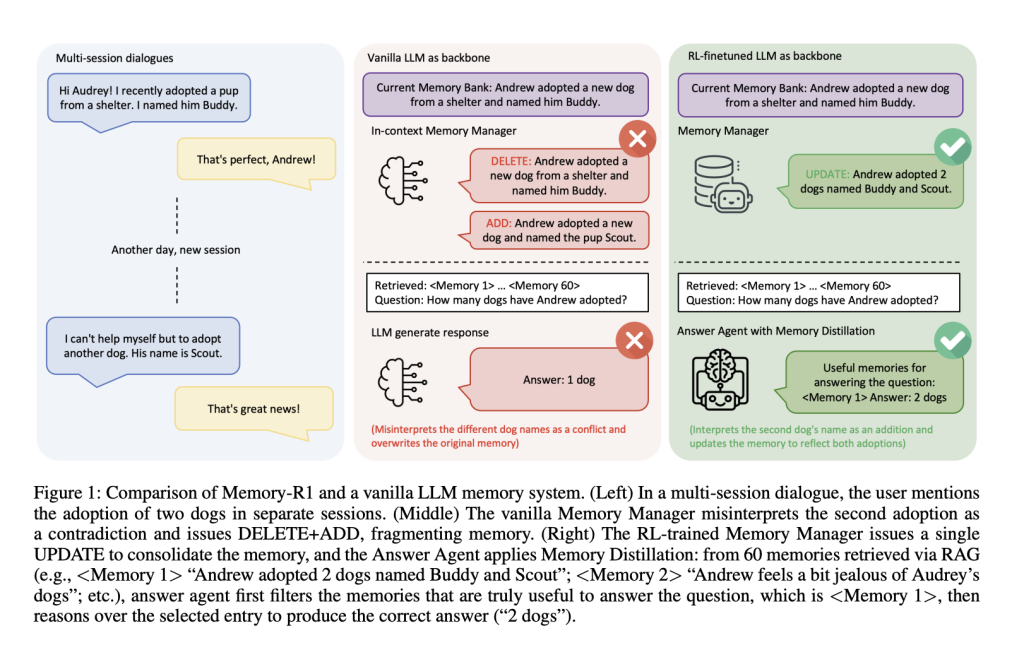
Imagine a multi-session conversation: in the first session, a user says, “I adopted a dog named Buddy.” Later, they add, “I adopted another dog named Scout.” Should the system replace the first statement with the second, merge them, or ignore the update? Vanilla memory pipelines often fail—they might erase “Buddy” and add “Scout,” misinterpreting the new information as a contradiction rather than a consolidation. Over time, such systems lose coherence, fragmenting user knowledge rather than evolving it.
RAG systems retrieve information but don’t filter it: irrelevant entries pollute reasoning, and the model gets distracted by noise. Humans, by contrast, retrieve widely but then selectively filter what matters. Most AI memory systems are static, relying on handcrafted heuristics for what to remember, rather than learning from feedback.
The Memory-R1 Framework
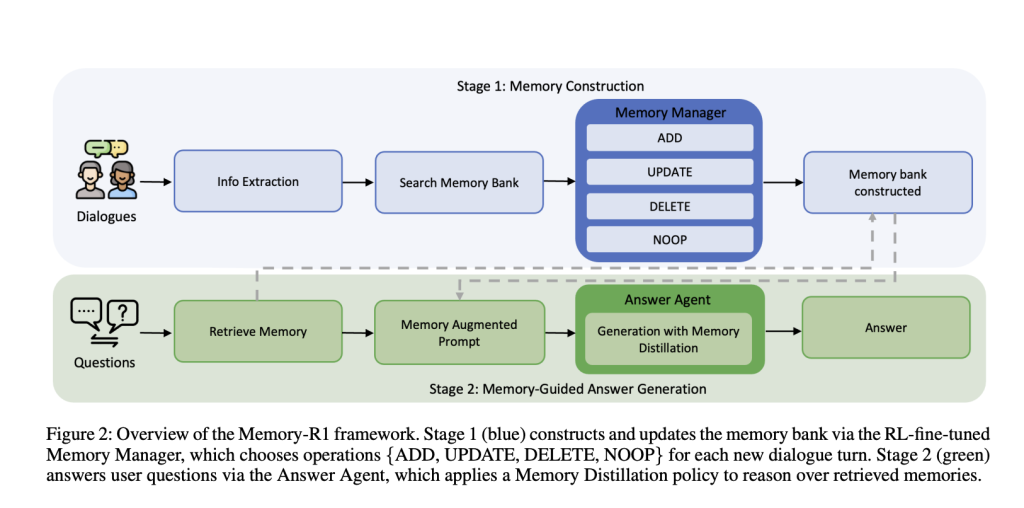
Memory-R1 is built around two specialized, RL-fine-tuned agents:
- Memory Manager: Decides which memory operations (ADD, UPDATE, DELETE, NOOP) to perform after each dialogue turn, updating the external memory bank dynamically.
- Answer Agent: For each user question, retrieves up to 60 candidate memories, distills them to the most relevant subset, then reasons over this filtered context to generate an answer.
Both components are trained with reinforcement learning RL—using either Proximal Policy Optimization (PPO) or Group Relative Policy Optimization (GRPO)—with only question-answer correctness as the reward signal. This means that, instead of requiring manually labeled memory operations, the agents learn by trial and error, optimizing for final task performance.
Memory Manager: Learning to Edit Knowledge
After each dialogue turn, an LLM extracts key facts. The Memory Manager then retrieves related entries from the memory bank, and chooses an operation:
- ADD: Insert new information not already present.
- UPDATE: Merge new details into existing memories when they elaborate or refine previous facts.
- DELETE: Remove outdated or contradictory information.
- NOOP: Leave memory unchanged if nothing relevant is added.
Training: The Memory Manager is updated based on the quality of answers the Answer Agent generates from the newly edited memory bank. If a memory operation enables the Answer Agent to respond accurately, the Memory Manager receives a positive reward. This outcome-driven reward eliminates the need for costly manual annotation of memory operations.
Example: When a user first mentions adopting a dog named Buddy, then later adds that they adopted another dog named Scout, a vanilla system might delete “Buddy” and add “Scout,” treating it as a contradiction. The RL-trained Memory Manager, however, updates the memory: “Andrew adopted two dogs, Buddy and Scout,” maintaining a coherent, evolving knowledge base.
Ablation: RL fine-tuning improves memory management significantly—PPO and GRPO both outperform in-context, heuristic-based managers. The system learns to consolidate rather than fragment knowledge.
Answer Agent: Selective Reasoning
For each question, the system retrieves up to 60 candidate memories with RAG. But instead of feeding all these to the LLM, the Answer Agent first distills the set—keeping only the most relevant entries. Only then does it generate an answer.
Training: The Answer Agent is also trained with RL, using the exact match between its answer and the gold answer as the reward. This encourages it to focus on filtering out noise and reasoning over high-quality context.
Example: Asked “Does John live close to a beach or the mountains?”, a vanilla LLM might output “mountains,” influenced by irrelevant memories. Memory-R1’s Answer Agent, however, surfaces only beach-related entries before answering, leading to a correct “beach” response.
Ablation: RL fine-tuning improves answer quality over static retrieval. Memory distillation (filtering out irrelevant memories) further boosts performance. The gains are even larger with a stronger memory manager, showing compounding improvements.
Training Data Efficiency
Memory-R1 is data-efficient: it achieves strong results with only 152 question-answer pairs for training. This is possible because the agent learns from outcomes, not from thousands of hand-labeled memory operations. Supervision is kept to a minimum, and the system scales to large, real-world dialogue histories.
The LOCOMO benchmark, used for evaluation, consists of multi-turn dialogues (about 600 turns per dialogue, 26,000 tokens on average) and associated QA pairs spanning single-hop, multi-hop, open-domain, and temporal reasoning—ideal for testing long-horizon memory management.
Experimental Results
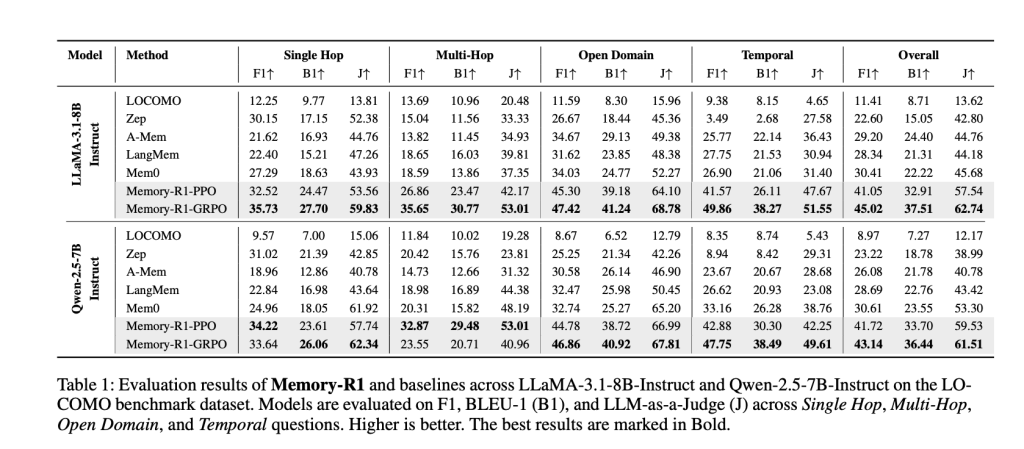
Memory-R1 was tested on LLaMA-3.1-8B-Instruct and Qwen-2.5-7B-Instruct backbones, against competitive baselines (LOCOMO, Zep, A-Mem, LangMem, Mem0). The key metrics are:
- F1: Measures overlap between predicted and correct answers.
- BLEU-1: Captures lexical similarity at the unigram level.
- LLM-as-a-Judge: Uses a separate LLM to evaluate factual accuracy, relevance, and completeness—a proxy for human judgment.
Results: Memory-R1-GRPO achieves the best overall performance, improving over Mem0 (the previous best baseline) by 48% in F1, 69% in BLEU-1, and 37% in LLM-as-a-Judge on LLaMA-3.1-8B. Similar gains are seen on Qwen-2.5-7B. The improvements are broad-based, spanning all question types, and generalize across model architectures.
Why This Matters
Memory-R1 shows that memory management and utilization can be learned—LLM agents don’t need to rely on brittle heuristics. By grounding decisions in outcome-driven RL, the system:
- Automatically consolidates knowledge as conversations evolve, rather than fragmenting or overwriting it.
- Filters out noise when answering, improving factual accuracy and reasoning quality.
- Learns efficiently with little supervision, and scales to real-world, long-horizon tasks.
- Generalizes across models, making it a promising foundation for the next generation of agentic, memory-aware AI systems.
Conclusion
Memory-R1 unshackles LLM agents from their stateless constraints, giving them the ability to learn—through reinforcement—how to manage and use long-term memories effectively. By framing memory operations and filtering as RL problems, it achieves state-of-the-art performance with minimal supervision and strong generalization. This marks a major step toward AI systems that not only converse fluently, but remember, learn, and reason like humans—offering richer, more persistent, and more useful experiences for users everywhere.
FAQs
FAQ 1: What makes Memory-R1 better than typical LLM memory systems?
Memory-R1 uses reinforcement learning to actively control memory—deciding which information to add, update, delete, or keep—enabling smarter consolidation and less fragmentation than static, heuristic-based approaches.
FAQ 2: How does Memory-R1 improve answer quality from long dialogue histories?
The Answer Agent applies a “memory distillation” policy: it filters up to 60 retrieved memories to surface only those most relevant for each question, reducing noise and improving factual accuracy compared to simply passing all context to the model.
FAQ 3: Is Memory-R1 data-efficient for training?
Yes, Memory-R1 achieves state-of-the-art gains using only 152 QA training pairs, as its outcome-based RL rewards eliminate the need for costly manual annotation of each memory operation.
Check out the Paper here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.