Using RouteLLM to Optimize LLM Usage
RouteLLM is a flexible framework for serving and evaluating LLM routers, designed to maximize performance while minimizing cost.
Key features:
- Seamless integration — Acts as a drop-in replacement for the OpenAI client or runs as an OpenAI-compatible server, intelligently routing simpler queries to cheaper models.
- Pre-trained routers out of the box — Proven to cut costs by up to 85% while preserving 95% of GPT-4 performance on widely used benchmarks like MT-Bench.
- Cost-effective excellence — Matches the performance of leading commercial offerings while being over 40% cheaper.
- Extensible and customizable — Easily add new routers, fine-tune thresholds, and compare performance across multiple benchmarks.
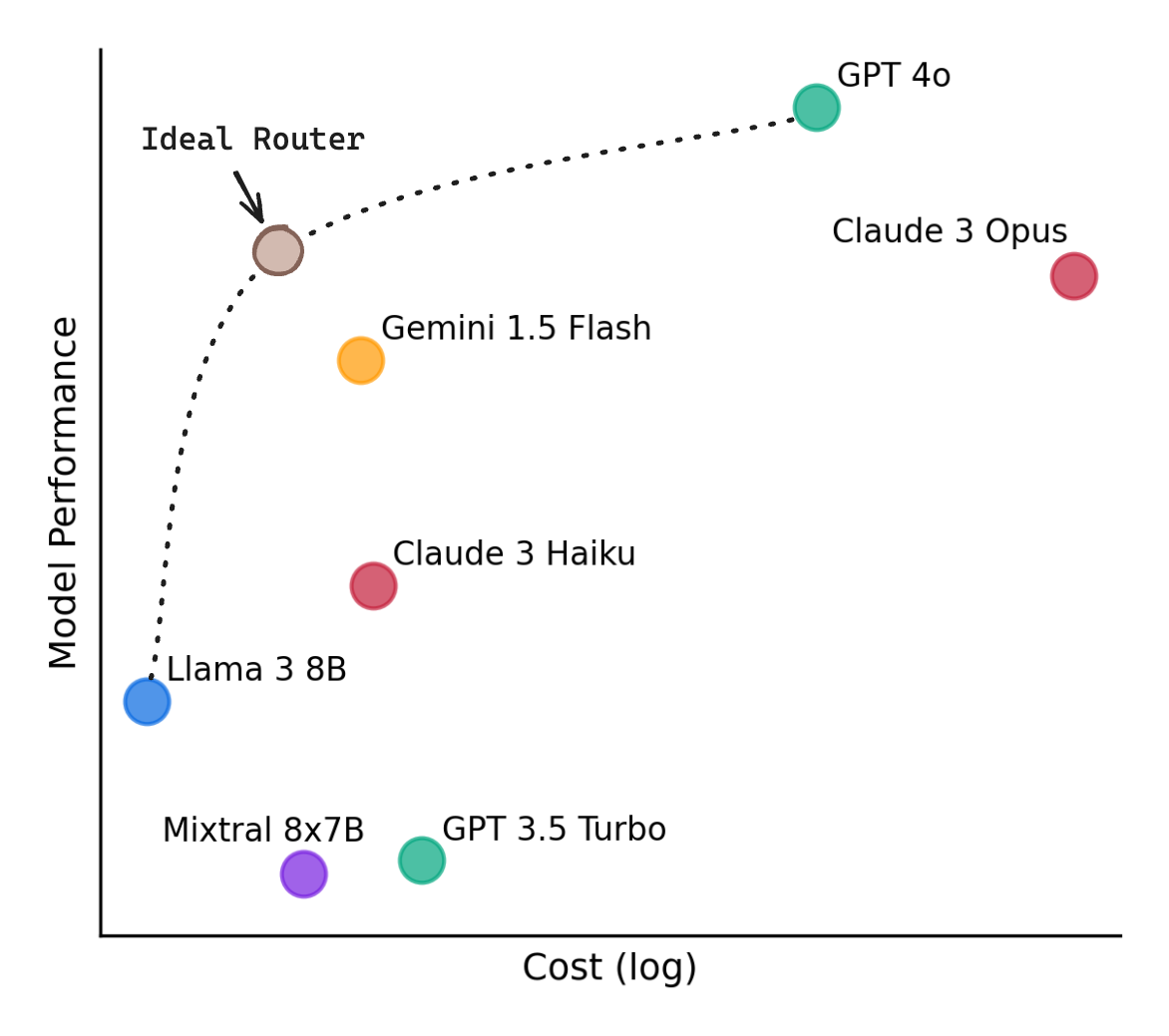
In this tutorial, we’ll walk through how to:
- Load and use a pre-trained router.
- Calibrate it for your own use case.
- Test routing behavior on different types of prompts.
- Check out the Full Codes here.
Installing the dependencies
!pip install "routellm[serve,eval]"Loading OpenAI API Key
To get an OpenAI API key, visit https://platform.openai.com/settings/organization/api-keys and generate a new key. If you’re a new user, you may need to add billing details and make a minimum payment of $5 to activate API access.
RouteLLM leverages LiteLLM to support chat completions from a wide range of both open-source and closed-source models. You can check out the list of providers at https://litellm.vercel.app/docs/providers if you want to use some other model. Check out the Full Codes here.
import os
from getpass import getpass
os.environ['OPENAI_API_KEY'] = getpass('Enter OpenAI API Key: ')Downloading Config File
RouteLLM uses a configuration file to locate pretrained router checkpoints and the datasets they were trained on. This file tells the system where to find the models that decide whether to send a query to the strong or weak model. Check out the Full Codes here.
Do I need to edit it?
For most users — no. The default config already points to well-trained routers (mf, bert, causal_llm) that work out of the box. You only need to change it if you plan to:
- Train your own router on a custom dataset.
- Replace the routing algorithm entirely with a new one.
For this tutorial, we’ll keep the config as is and simply:
- Set our strong and weak model names in code.
- Add our API keys for the chosen providers.
- Use a calibrated threshold to balance cost and quality.
- Check out the Full Codes here.
!wget https://raw.githubusercontent.com/lm-sys/RouteLLM/main/config.example.yamlInitializing the RouteLLM Controller
In this code block, we import the necessary libraries and initialize the RouteLLM Controller, which will manage how prompts are routed between models. We specify routers=[“mf”] to use the Matrix Factorization router, a pretrained decision model that predicts whether a query should be sent to the strong or weak model.
The strong_model parameter is set to “gpt-5”, a high-quality but more expensive model, while the weak_model parameter is set to “o4-mini”, a faster and cheaper alternative. For each incoming prompt, the router evaluates its complexity against a threshold and automatically chooses the most cost-effective option—ensuring that simple tasks are handled by the cheaper model while more challenging ones get the stronger model’s capabilities.
This configuration allows you to balance cost efficiency and response quality without manual intervention. Check out the Full Codes here.
import os
import pandas as pd
from routellm.controller import Controller
client = Controller(
routers=["mf"], # Model Fusion router
strong_model="gpt-5",
weak_model="o4-mini"
)!python -m routellm.calibrate_threshold --routers mf --strong-model-pct 0.1 --config config.example.yamlThis command runs RouteLLM’s threshold calibration process for the Matrix Factorization (mf) router. The –strong-model-pct 0.1 argument tells the system to find the threshold value that routes roughly 10% of queries to the strong model (and the rest to the weak model).
Using the –config config.example.yaml file for model and router settings, the calibration determined:
For 10% strong model calls with mf, the optimal threshold is 0.24034.
This means that any query with a router-assigned complexity score above 0.24034 will be sent to the strong model, while those below it will go to the weak model, aligning with your desired cost–quality trade-off.
Defining the threshold & prompts variables
Here, we define a diverse set of test prompts designed to cover a range of complexity levels. They include simple factual questions (likely to be routed to the weak model), medium reasoning tasks (borderline threshold cases), and high-complexity or creative requests (more suited for the strong model), along with code generation tasks to test technical capabilities. Check out the Full Codes here.
threshold = 0.24034
prompts = [
# Easy factual (likely weak model)
"Who wrote the novel 'Pride and Prejudice'?",
"What is the largest planet in our solar system?",
# Medium reasoning (borderline cases)
"If a train leaves at 3 PM and travels 60 km/h, how far will it travel by 6:30 PM?",
"Explain why the sky appears blue during the day and red/orange during sunset.",
# High complexity / creative (likely strong model)
"Write a 6-line rap verse about climate change using internal rhyme.",
"Summarize the differences between supervised, unsupervised, and reinforcement learning with examples.",
# Code generation
"Write a Python function to check if a given string is a palindrome, ignoring punctuation and spaces.",
"Generate SQL to find the top 3 highest-paying customers from a 'sales' table."
]Evaluating Win Rate
The following code calculates the win rate for each test prompt using the mf router, showing the likelihood that the strong model will outperform the weak model.
Based on the calibrated threshold of 0.24034, two prompts —
“If a train leaves at 3 PM and travels 60 km/h, how far will it travel by 6:30 PM?” (0.303087)
“Write a Python function to check if a given string is a palindrome, ignoring punctuation and spaces.” (0.272534)
— exceed the threshold and would be routed to the strong model.
All other prompts remain below the threshold, meaning they would be served by the weaker, cheaper model. Check out the Full Codes here.
win_rates = client.batch_calculate_win_rate(prompts=pd.Series(prompts), router="mf")
# Store results in DataFrame
_df = pd.DataFrame({
"Prompt": prompts,
"Win_Rate": win_rates
})
# Show full text without truncation
pd.set_option('display.max_colwidth', None)These results also help in fine-tuning the routing strategy — by analyzing the win rate distribution, we can adjust the threshold to better balance cost savings and performance.
Routing Prompts Through Calibrated Model Fusion (MF) Router
This code iterates over the list of test prompts and sends each one to the RouteLLM controller using the calibrated mf router with the specified threshold (router-mf-{threshold}).
For each prompt, the router decides whether to use the strong or weak model based on the calculated win rate.
The response includes both the generated output and the actual model that was selected by the router.
These details — the prompt, model used, and generated output — are stored in the results list for later analysis. Check out the Full Codes here.
results = []
for prompt in prompts:
response = client.chat.completions.create(
model=f"router-mf-{threshold}",
messages=[{"role": "user", "content": prompt}]
)
message = response.choices[0].message["content"]
model_used = response.model # RouteLLM returns the model actually used
results.append({
"Prompt": prompt,
"Model Used": model_used,
"Output": message
})
df = pd.DataFrame(results)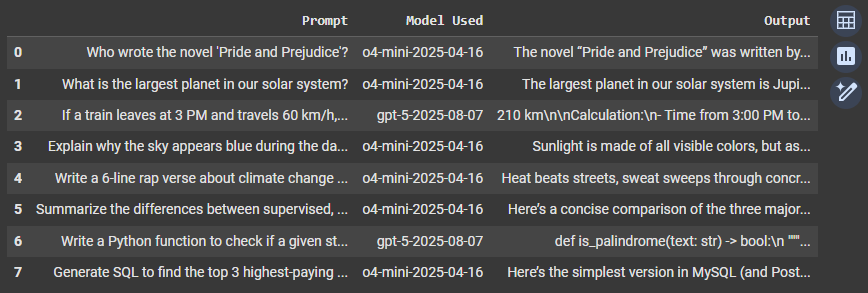
In the results, prompts 2 and 6 exceeded the threshold win rate and were therefore routed to the gpt-5 strong model, while the rest were handled by the weaker model.
Check out the Full Codes here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.