Meet Kosmos: An AI Scientist that Automates Data-Driven Discovery
Kosmos, built by Edison Scientific, is an autonomous discovery system that runs long research campaigns on a single goal. Given a dataset and an open ended natural language objective, it performs repeated cycles of data analysis, literature search, and hypothesis generation, then synthesizes the results into a fully cited scientific report. A typical run lasts up to 12 hours, includes about 200 agent rollouts, executes about 42,000 lines of code, and reads about 1,500 papers.
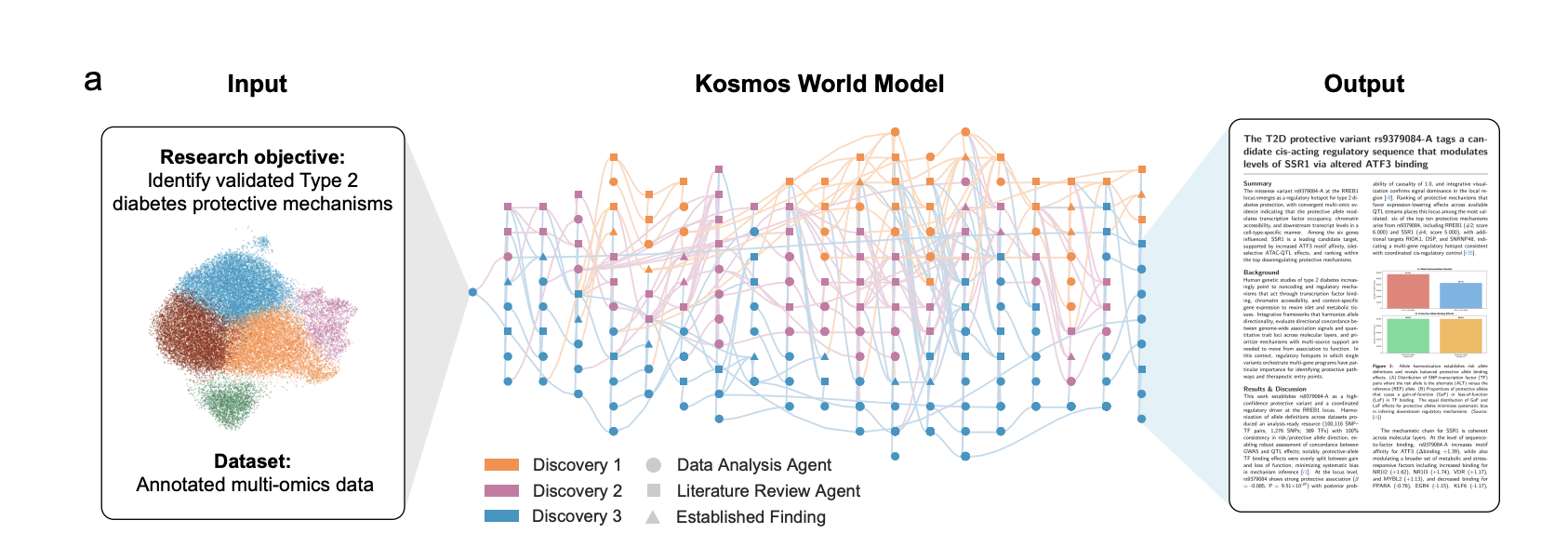
Architecture, world model, and agent roles
The core design choice is a structured world model that acts as long term memory for the system. The world model is a database of entities, relationships, experimental results, and open questions that is updated after every task. Unlike a plain context window, it is queryable and structured, so information from early steps remains accessible after tens of thousands of tokens.
Kosmos uses two main agents, a data analysis agent and a literature search agent. Each cycle, the system proposes up to 10 concrete tasks based on the research objective and the current world model. Examples include running a differential abundance analysis on a metabolomics dataset, or searching for pathways that connect a candidate gene to a disease phenotype. Agents write code, run it in a notebook environment, or retrieve and read papers, then write back structured outputs and citations into the world model.
This loop repeats for many cycles. At the end of the run, a separate synthesis component traverses the world model and emits a report where every statement is linked either to a Jupyter notebook cell or to a specific passage in the primary literature. This explicit provenance is important in scientific settings because it allows human collaborators to audit individual claims instead of treating the system as a black box.
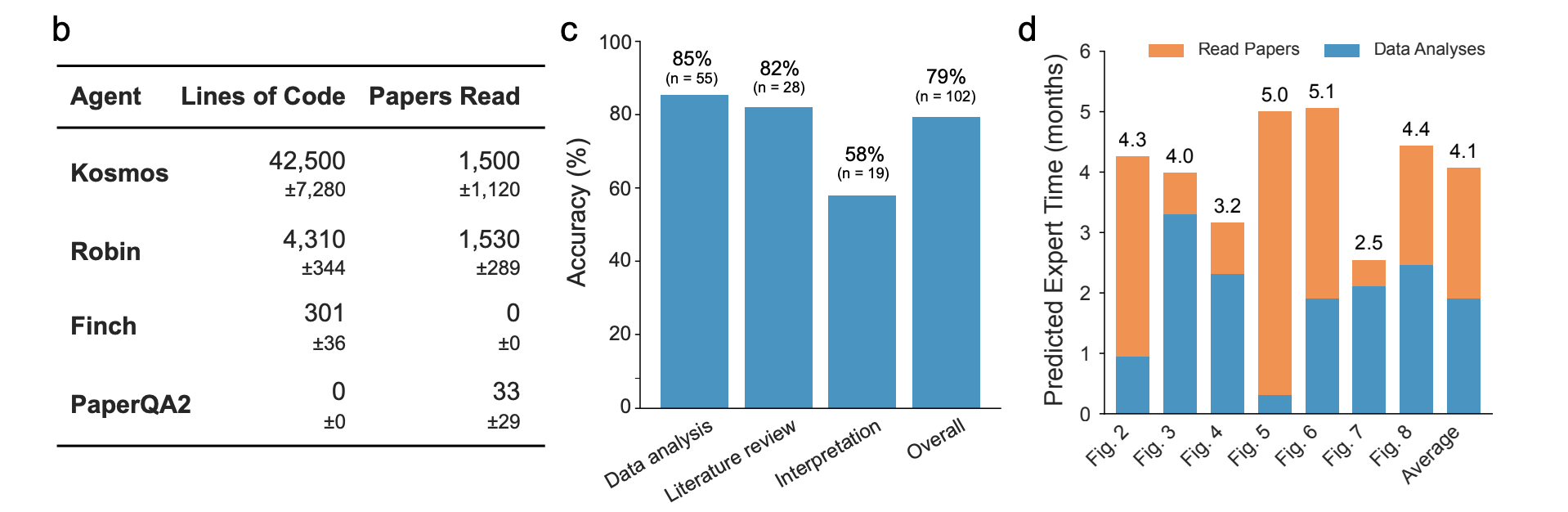
Accuracy and research time equivalence
The team evaluates report quality by sampling 102 statements from 3 representative Kosmos reports and asking domain experts to classify each statement as supported or refuted. Overall, 79.4 percent of statements are judged accurate. Data analysis statements are the most reliable at about 85.5 percent, literature statements are correct about 82.1 percent of the time, and synthesis statements that combine evidence are correct about 57.9 percent of the time.
To estimate human equivalent effort, the authors assume 2 hours for a typical data analysis trajectory and 15 minutes for reading a paper, then count trajectories and papers per run. This yields about 4.1 expert months for a typical run, assuming a 40 hour work week. In a separate survey, 7 collaborating scientists rate a 20 step Kosmos run as equivalent to about 6.14 months of their own work on the same objective, and this perceived effort scales roughly linearly with the number of cycles up to 20.
Representative discoveries
Kosmos is tested on 7 case studies that span metabolomics, materials science, neuroscience, statistical genetics, and neurodegeneration. In 3 cases, it independently reproduces prior human results without accessing the original preprints during the run. In 4 cases, it proposes mechanisms that the authors describe as novel contributions to the literature.
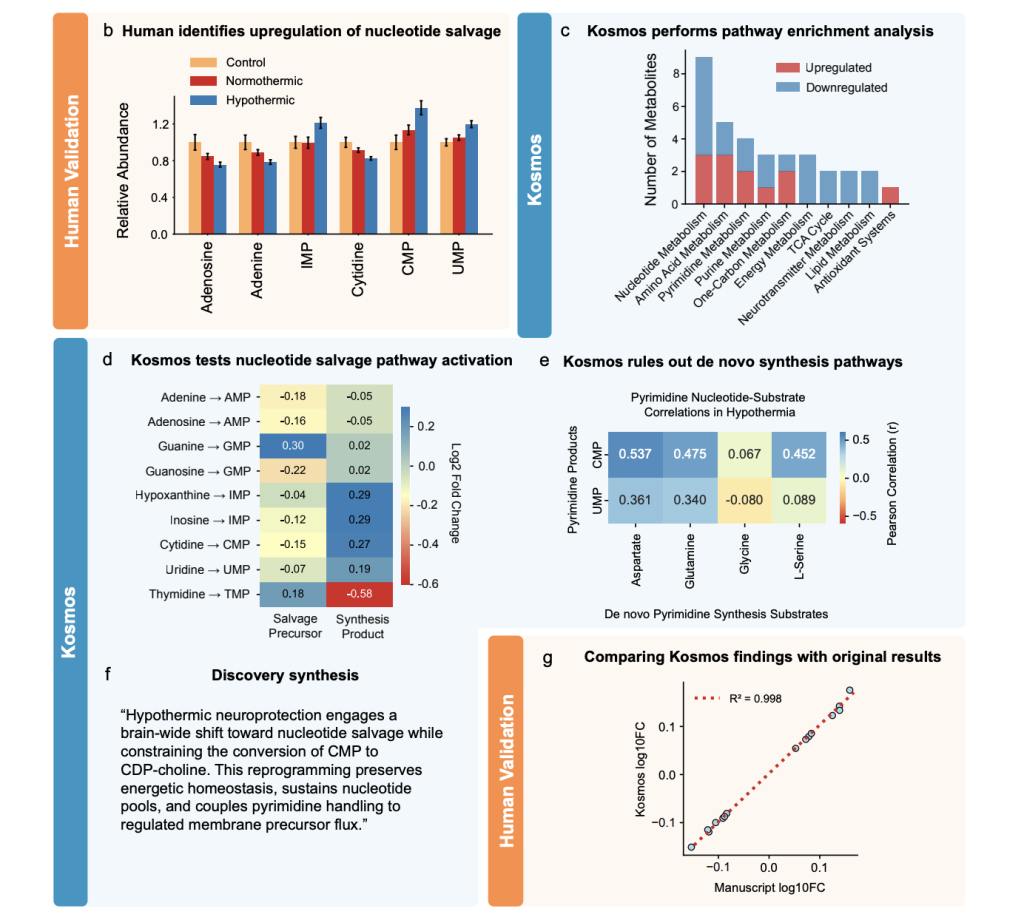
In the first discovery, Kosmos analyzes metabolomics data from a mouse hypothermia experiment. It identifies nucleotide metabolism as the dominant altered pathway in hypothermic brains, with decreased precursor bases and nucleosides and increased monophosphate products. The system concludes that nucleotide salvage pathways dominate over de novo synthesis during protective hypothermia, which matches an independent human analysis that was unpublished at the time of the run.
In the second discovery, Kosmos analyzes environmental logs from a perovskite solar cell fabrication system. It recovers the human result that absolute humidity during thermal annealing is the main determinant of device efficiency and identifies a critical humidity threshold described as a fatal filter, beyond which devices fail. This finding matches a preprint in materials science that was not accessible to Kosmos at runtime due to model training cutoffs and retrieval constraints.
In the third discovery, Kosmos is given neuron level reconstructions across several species and fits distributions for neurite length, degree, and synapse counts. It concludes that degree and synapse distributions are better modeled as log normal rather than scale free and recovers power law scaling between neurite length and synapse count in most datasets. These results align with the connectivity rules reported in an earlier neuroscience preprint.
The remaining four discoveries are described as novel. They include a Mendelian randomization analysis that implicates circulating superoxide dismutase 2 as a protective factor for myocardial fibrosis, the definition of a Mechanistic Ranking Score that integrates posterior inclusion probabilities and multiomic evidence for type 2 diabetes loci, a proteomic analysis that orders molecular events along a pseudotime axis in Alzheimer disease, and a large scale single nucleus transcriptomic analysis that links age related loss of flippase expression and exposure of phosphatidylserine signals to entorhinal cortex neuron vulnerability.
Key Takeaways
- Kosmos is an autonomous AI scientist that runs up to 12 hours per objective, executing about 42,000 lines of code and reading about 1,500 papers per run, coordinated through a structured world model.
- The system uses parallel data analysis and literature search agents that share a central world model, which lets Kosmos maintain coherent long horizon reasoning across about 200 agent rollouts.
- Expert evaluators found 79.4 percent of sampled report statements to be accurate, with data analysis and literature statements above 80 percent accuracy, while interpretation statements remain less reliable.
- A 20 cycle Kosmos run is rated by collaborators as equivalent to about 6 months of expert research effort, and the number of valuable findings scales approximately linearly with cycle count up to 20.
- Across 7 case studies in metabolomics, materials science, neuroscience, statistical genetics, and neurodegeneration, Kosmos both reproduces unpublished or post cutoff results and proposes novel mechanisms, while still requiring human scientists for dataset selection and validation.
Kosmos shows what happens when a structured world model and domain agnostic Edison agents are pushed to the limits of current LLM tooling, it delivers measurable gains in reasoning depth, reproducibility, and traceability while still depending on scientists for data curation, objective setting, and interpretation of synthesis statements that remain less reliable than data analysis and literature statements. Overall, Kosmos is a strong template for AI accelerated science, not a replacement for human researchers.
Check out the Paper and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.