ByteDance Unveils ToolTrain: A New Tool-Integrated Reinforcement Learning RL Framework that Redefines Repo Deep Search
Issue localization involves identifying exact code locations that require modification to fix software problems, a process that often demands significant manual effort from developers, especially in large repositories. Due to its complexity and time-intensive nature, automating this task has become a key research focus. LLM-based agents enable language models to use various tools for dynamic repository exploration. However, these models face challenges in performing Repo Deep Search, a sequential navigation task that requires multi-step reasoning and effective tool usage. Current LLMs struggle with these high demands, often resulting in incorrect tool calls or a breakdown in maintaining coherent reasoning chains during the exploration process.
Existing work includes fault localization and agentic training. In fault localization, methods like DeepFL and DeepRL4FL utilize deep neural networks and CNNs to identify faulty code by analyzing test coverage, data dependencies, and static code representations. More recent advancements include LLMs, such as Agentless, to narrow down code locations. LLMs often lack the complexity needed for complex reasoning and tool usage in repository exploration. To address this, agentic training methods, such as SWE-Gym and SEAlign, fine-tune LLMs using high-quality trajectories. Another approach, LocAgent, constructs the ground truth for issue localization based on functions modified by golden patches from GitHub.
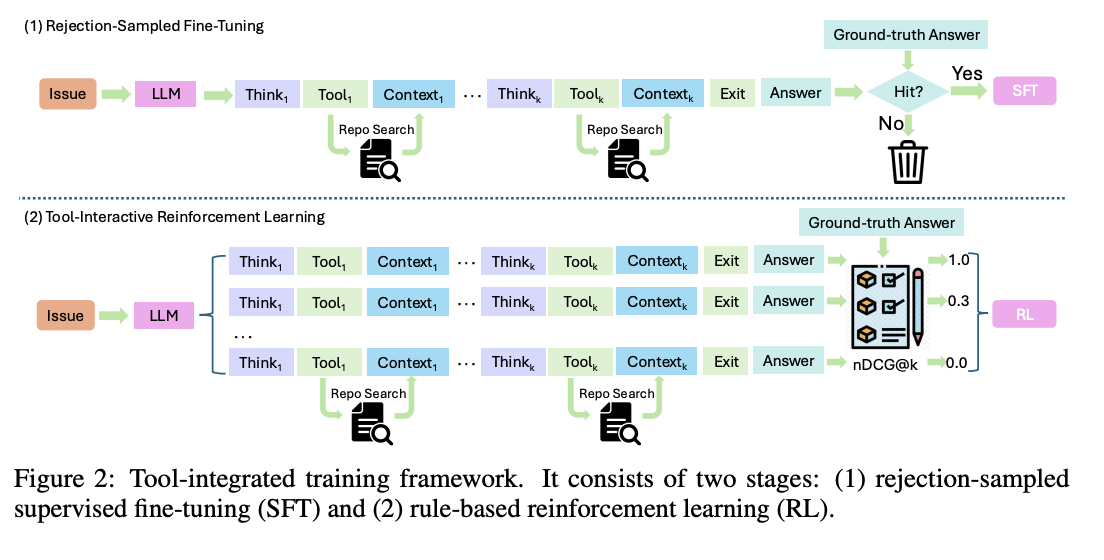
Researchers from Peking University, ByteDance, and Beijing Institute of Technology have proposed ToolTrain, a tool-integrated training framework to enhance the multi-hop reasoning capabilities of LLMs during issue localization. ToolTrain introduces RepoSearcher, a lightweight agent equipped with simple retrieval tools that enable LLMs to locate function or class definitions by name. To help the LLMs use these tools for multi-hop reasoning, the researchers construct labeled data from open-source repositories and follow a two-stage process: rejection-sampled SFT and tool-integrated RL. This approach ensures the model learns to use tools strategically, avoiding redundant explorations while focusing on promising code paths.
Researchers construct their evaluation dataset using SWE-Bench-Verified, a benchmark derived from real GitHub issues and manually verified by professional developers. This dataset provides ground-truth answers for issue localization by identifying functions and files modified in golden patches. To evaluate RepoSearcher’s performance, metrics such as Recall@k, MAP, MRR, nDCG@k, and %Resolved are used. Moreover, ToolTrain is applied to two models, Qwen-7B and Qwen-32B, which are then compared against four state-of-the-art frameworks: Agentless, CrcaLoca, CoSIL, and LocAgent. These baselines represent diverse design philosophies, ensuring a detailed evaluation of ToolTrain’s effectiveness for precise and strategic code exploration.
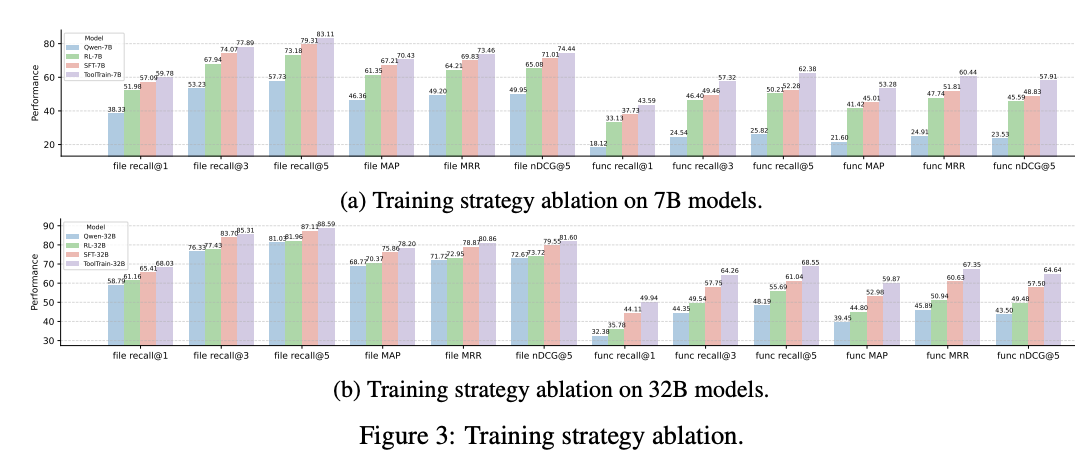
The RepoSearcher with ToolTrain achieves state-of-the-art performance among models of similar size and even outperforms larger commercial models on specific metrics. For instance, RepoSearcher with ToolTrain-32B achieves a function-level Recall@5 score of 68.55, surpassing Claude-3.7-Sonnet (66.38). The 7B-parameter model outperforms other frameworks using 32B models, enhancing the tool-calling capabilities of ToolTrain in smaller models. In issue resolution, RepoSearcher with ToolTrain-7B achieves a Recall@5 of 62.38 and a resolution rate of 14.00, the best among 7B models. However, disparities arise when using different patch generation models, as seen in the resolution rates of 14.00 (ToolTrain-7B) versus 31.60 (ToolTrain-32B), despite similar localization results.
In conclusion, researchers introduced ToolTrain to enhance the issue localization of LLMs. By combining SFT with RL, ToolTrain equips models like RepoSearcher to navigate code repositories effectively and perform precise multi-hop reasoning. Evaluated on real-world benchmarks, ToolTrain-trained models achieve state-of-the-art performance among similarly sized models and even outperform larger commercial models like Claude-3.7 on specific tasks. This shows its ability to optimize tool usage and reasoning in smaller models, reducing redundancy and improving efficiency. The study emphasizes the potential of ToolTrain to transform issue localization and provide an efficient solution for complex software challenges.
Check out the Paper and GitHub Page here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.