How Powerful are Diffusion LLMs? Rethinking Generation with Any-Process Masked Diffusion Models
How powerful are Diffusion LLMs compared to classic autoregressive LLMs, once you treat generation as an algorithm with time and space complexity, not just as a decoding trick? A new research paper from a team researchers from Toyota Technological Institute at Chicago and MIT gives a formal answer. This new research compares Auto-Regressive Models (ARM), Masked Diffusion Models (MDM), and a new family called Any-Process MDM (AP-MDM), using complexity theory and controlled reasoning tasks.
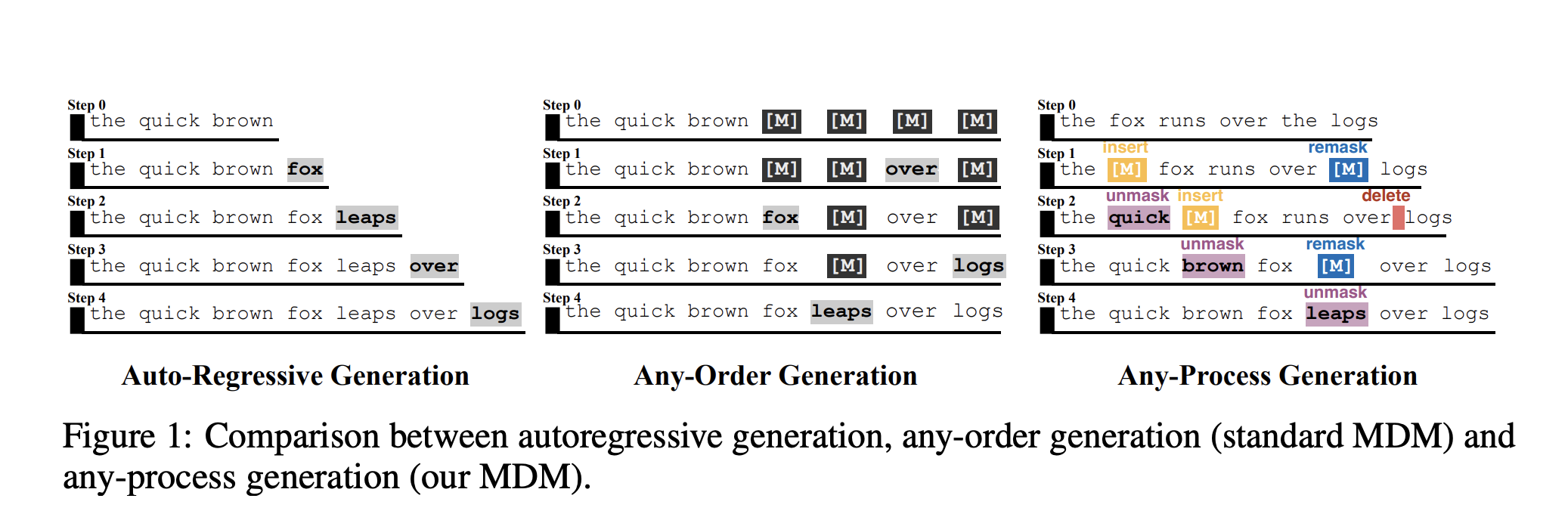
ARM vs MDM: Same Expressivity, Different Parallel Time
ARM uses next token prediction in a strict left to right order. Prior work already shows that with enough intermediate steps, ARM is Turing complete, so it can represent any computable function in principle, given enough context and compute.
MDM, the discrete diffusion style used in diffusion LLMs, works on a masked sequence. The model starts from a fully masked sequence and iteratively unmasks tokens. It can update many positions in parallel and in any order. MDM is modeled as an encoder only Transformer with context length (S(n)) and decoding steps (T(n)) for an input of size (n).
The research team shows:
- MDM can simulate any PRAM (Parallel Random Access Machine) algorithm with parallel time (T(n)) using (O(T(n))) diffusion steps and context (S(n)) proportional to total work.
- This makes MDM Turing complete and lets it match ideal parallel time on problems in NC, such as graph connectivity and some context free language tasks, where ARM needs time linear in sequence length.
Diffusion LLMs therefore gain efficiency on parallelizable problems, not extra expressive power by themselves.
Any-Order Generation Has Limited Benefits
A natural question is whether Any-Order Generation is strictly more powerful than left to right generation.
To isolate this, the research team defines an Any-Order MDM (AO-MDM) and a corresponding Masked ARM with the same architecture and similar token budget, but decoding in a fixed left to right way over a sequence padded with masks.
The main result:
- Any computation performed by AO-MDM with one token per step and context (S(n)) can be reorganized into a left to right schedule and simulated by a Masked ARM with sequence length (O(S(n))) plus a constant number of extra layers.
In other words, once you control for parallelism and architecture, any order generation alone does not expand the class of problems beyond what ARM can already handle.
Both ARM and AO-MDM also share a space limitation. With context length (S(n)), they cannot efficiently solve problems that require more than roughly (S(n)3) serial time. With polynomial context, they are effectively limited to problems in the class P and cannot handle general NP hard tasks just by test time scaling.
Any-Process Generation and AP-MDM
To go beyond these limits, the research team proposes Any-Process Generation, instantiated as Any-Process MDM (AP-MDM).
AP-MDM keeps the masked diffusion view but extends the transition function with three extra operations, in addition to the usual unmask:
- remask: turn an already decoded token back into the mask token
M - insert: insert a new mask token at a chosen position
- delete: delete a mask token that is no longer needed
These are controlled by a 3 bit vector per position (ct,i = (ct,i[1], ct,i[2], ct,i[3]). The same Transformer backbone predicts both content logits and these control bits.
remaskuses the first bit to decide whether to overwrite a position withM, which enables backtracking and self correction.insertanddeleteuse the second and third bits to add or remove mask tokens, so the sequence length can grow or shrink during decoding.
Architecturally, AP-MDM only adds three small linear heads on top of an encoder only Transformer, so it is easy to add on top of existing MDM style diffusion LLMs.

The key theoretical result:
- AP-MDM can simulate any PRAM algorithm with optimal parallel time and optimal space, using context proportional to the true space (S(n)) rather than total work. With polynomial context, AP-MDM can realize computations in PSPACE, while standard MDM and ARM under the same context budget are restricted to P.
The research team also tried to prove that there exists a constant depth AP-MDM whose generation process cannot be simulated by any constant depth ARM or Masked ARM, under standard complexity assumptions.
Empirical Results: Sudoku, Dyck, Graphs, Parity
The experiments match the theory and make the differences concrete.
Sudoku
Sudoku, generalized to (n2 x n2) grids, is NP complete.
- AP-MDM reaches 99.28 percent accuracy with about 1.2 million parameters and only 100 training instances.
- An ARM baseline with ordering reaches 87.18 percent using 1.8 million training instances and about 5 times more parameters.
- The best AO-MDM baseline reaches 89.49 percent under the same large data regime.
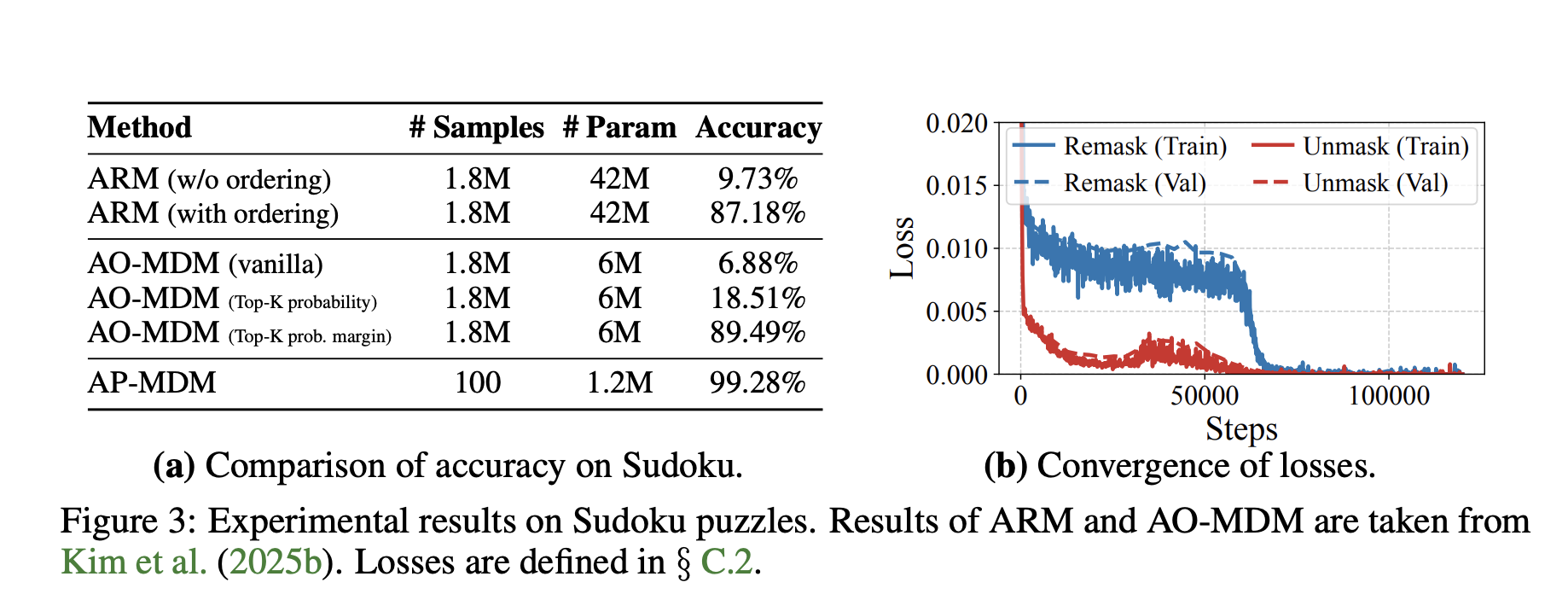
This shows that editing operations, especially remask, are crucial to exploit test time scaling on hard reasoning tasks.
Dyck languages and coding style constraints
The research also analyzes two sided Dyck k languages, which model matched parentheses and are a core abstraction for code syntax. It proves that fixed ARM models cannot ensure valid generation for arbitrary lengths, while there exists an AP-MDM that generates exactly the Dyck language using insert and remask.
This matches how coding tasks require structure aware edits under global constraints, for example balanced brackets and consistent scopes.
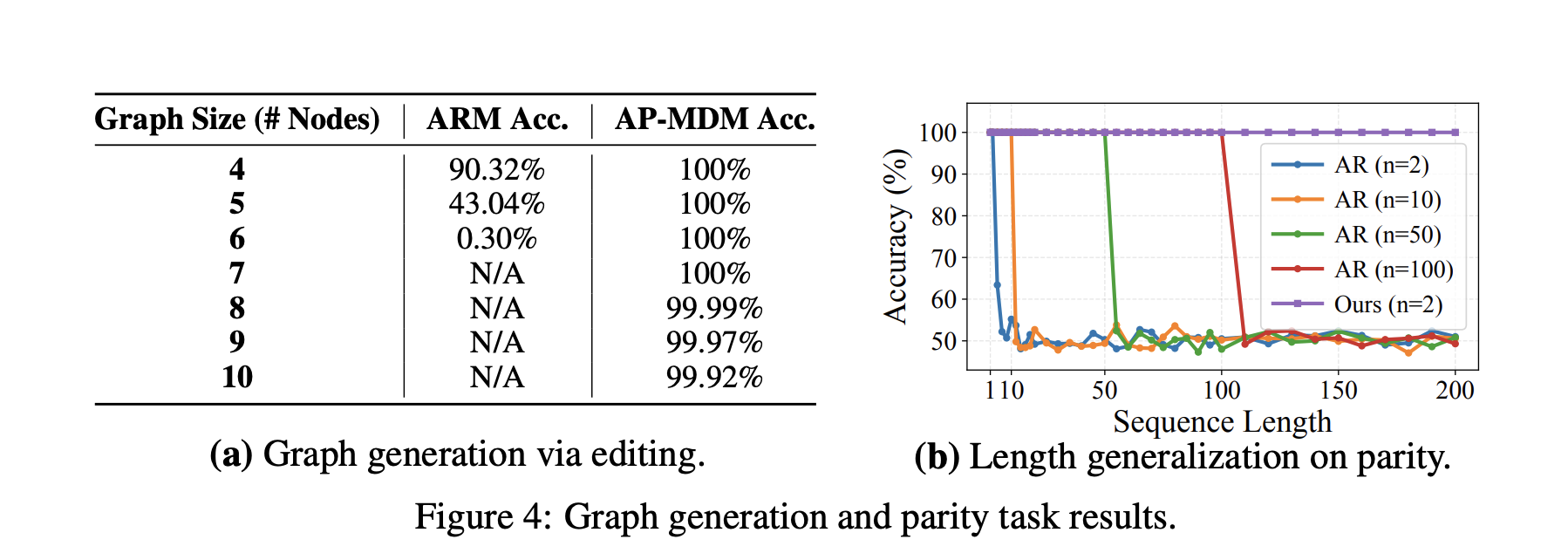
Graph generation and structural editing
For graph editing tasks under global constraints, AP-MDM uses insert, delete and remask to implement a sequence of structured edits over a graph representation. The reported accuracy stays near perfect as graph size scales, while ARM degrades as the graph gets larger.
Parity and length generalization
On parity, AP-MDM learns a local elimination rule by repeatedly deleting pairs of bits, driven by remask and delete. It is trained only on length 2 sequences, then achieves 100 percent generalization to arbitrary lengths. ARM baselines struggle to reach similar generalization even with much longer training sequences.
Key Takeaways
- Any order Masked Diffusion Models are as expressive as autoregressive models once you fix architecture and parallelism, they mainly provide parallel efficiency rather than new computational power.
- Masked Diffusion Models can simulate PRAM algorithms and achieve exponential speedup on parallelizable tasks in NC, but with polynomial context they remain effectively limited to problems in class P, similar to autoregressive models.
- Any Process MDM extends diffusion LLMs with remask, insert and delete operations, implemented via a three bit control vector per token, and can simulate PRAM with both optimal parallel time and optimal space, reaching PSPACE level expressivity under polynomial context.
- On hard reasoning tasks such as generalized Sudoku, Dyck languages, graph editing and parity, AP MDM shows strong empirical advantages, for example achieving about 99.28 percent Sudoku accuracy with only 100 training instances and a much smaller parameter budget than autoregressive and any order MDM baselines.
- For domains like coding, mathematics and AI4Science that involve structured edits and revision histories, AP MDM aligns better with the underlying generation processes than next token prediction, and its editing operations are provably hard to simulate with constant depth autoregressive models.
Any-Process MDM is an important step because it treats generation as a full algorithm, not just a decoding order. The research work shows that Masked Diffusion Models already match PRAM parallel time, but remain in P under polynomial context, similar to autoregressive models. By adding remask, insert and delete, AP-MDM reaches PSPACE-level expressivity with polynomial context and achieves strong empirical gains on Sudoku, Dyck, graph editing and parity. Overall, AP-MDM makes a strong case that future frontier LLMs should adopt edit-based Any-Process Generation, not just faster autoregression.
Check out the Paper and Repo. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is committed to harnessing the potential of Artificial Intelligence for social good. His most recent endeavor is the launch of an Artificial Intelligence Media Platform, Marktechpost, which stands out for its in-depth coverage of machine learning and deep learning news that is both technically sound and easily understandable by a wide audience. The platform boasts of over 2 million monthly views, illustrating its popularity among audiences.