This AI Paper Proposes a Novel Dual-Branch Encoder-Decoder Architecture for Unsupervised Speech Enhancement (SE)
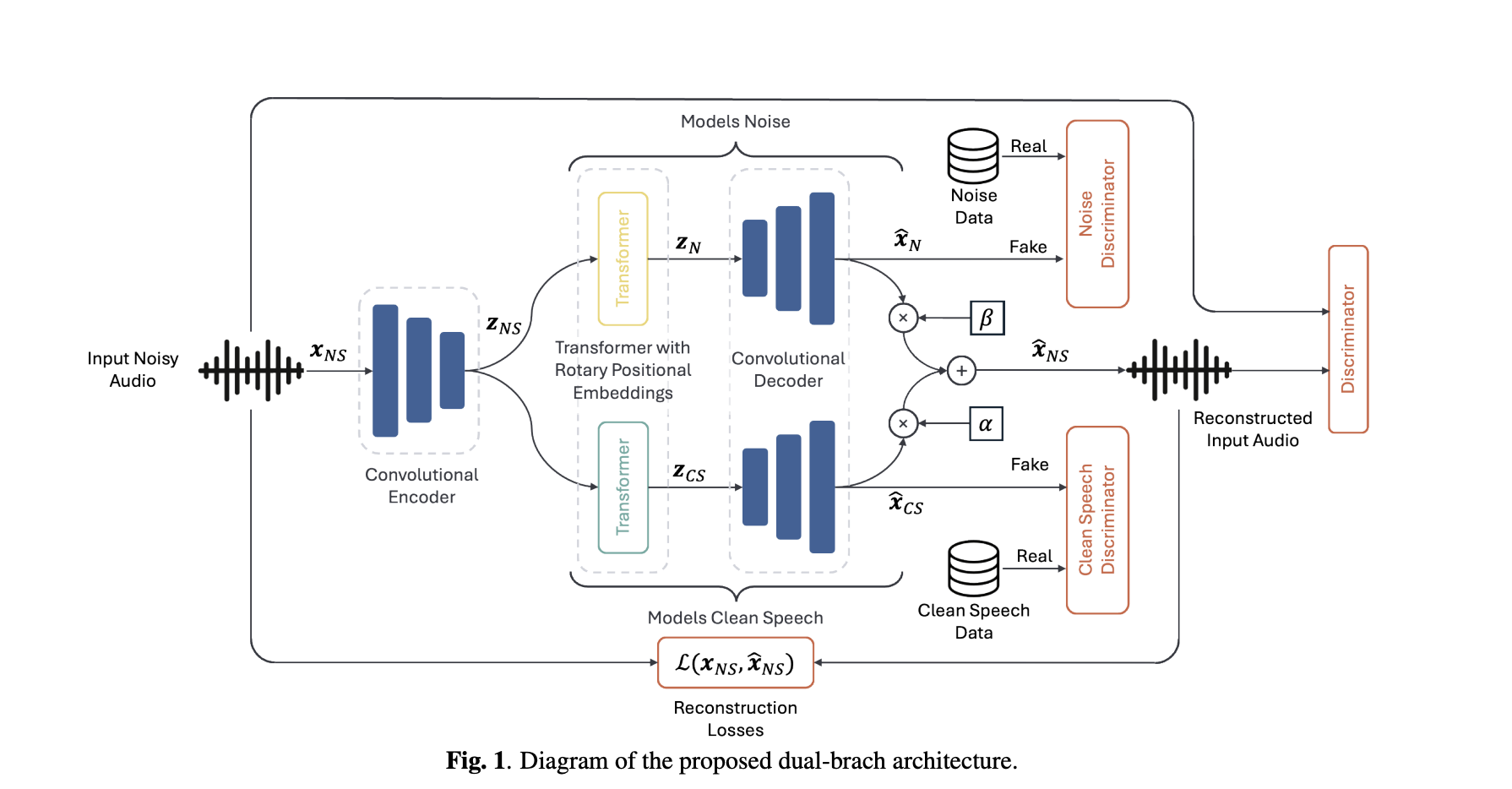
Can a speech enhancer trained only on real noisy recordings cleanly separate speech and noise—without ever seeing paired data? A team of researchers from Brno University of Technology and Johns Hopkins University proposes Unsupervised Speech Enhancement using Data-defined Priors (USE-DDP), a dual-stream encoder–decoder that separates any noisy input into two waveforms—estimated clean speech and residual noise—and learns both solely from unpaired datasets (clean-speech corpus and optional noise corpus). Training enforces that the sum of the two outputs reconstructs the input waveform, avoiding degenerate solutions and aligning the design with neural audio codec objectives.
Why this is important?
Most learning-based speech enhancement pipelines depend on paired clean–noisy recordings, which are expensive or impossible to collect at scale in real-world conditions. Unsupervised routes like MetricGAN-U remove the need for clean data but couple model performance to external, non-intrusive metrics used during training. USE-DDP keeps the training data-only, imposing priors with discriminators over independent clean-speech and noise datasets and using reconstruction consistency to tie estimates back to the observed mixture.
How it works?
- Generator: A codec-style encoder compresses the input audio into a latent sequence; this is split into two parallel transformer branches (RoFormer) that target clean speech and noise respectively, decoded by a shared decoder back to waveforms. The input is reconstructed as the least-squares combination of the two outputs (scalars α, β compensate for amplitude errors). Reconstruction uses multi-scale mel/STFT and SI-SDR losses, as in neural audio codecs.
- Priors via adversaries: Three discriminator ensembles—clean, noise, and noisy—impose distributional constraints: the clean branch must resemble the clean-speech corpus; the noise branch must resemble a noise corpus; the reconstructed mixture must sound natural. LS-GAN and feature-matching losses are used.
- Initialization: Initializing encoder/decoder from a pretrained Descript Audio Codec improves convergence and final quality vs. training from scratch.
How it compares?
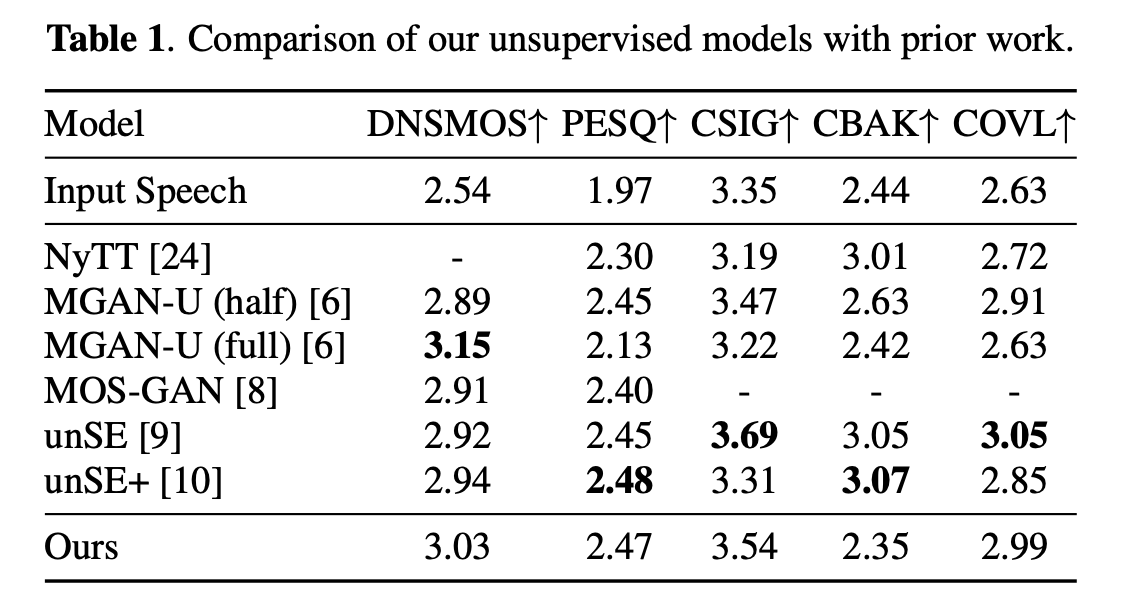
On the standard VCTK+DEMAND simulated setup, USE-DDP reports parity with the strongest unsupervised baselines (e.g., unSE/unSE+ based on optimal transport) and competitive DNSMOS vs. MetricGAN-U (which directly optimizes DNSMOS). Example numbers from the paper’s Table 1 (input vs. systems): DNSMOS improves from 2.54 (noisy) to ~3.03 (USE-DDP), PESQ from 1.97 to ~2.47; CBAK trails some baselines due to more aggressive noise attenuation in non-speech segments—consistent with the explicit noise prior.
Data choice is not a detail—it’s the result
A central finding: which clean-speech corpus defines the prior can swing outcomes and even create over-optimistic results on simulated tests.
- In-domain prior (VCTK clean) on VCTK+DEMAND → best scores (DNSMOS ≈3.03), but this configuration unrealistically “peeks” at the target distribution used to synthesize the mixtures.
- Out-of-domain prior → notably lower metrics (e.g., PESQ ~2.04), reflecting distribution mismatch and some noise leakage into the clean branch.
- Real-world CHiME-3: using a “close-talk” channel as in-domain clean prior actually hurts—because the “clean” reference itself contains environment bleed; an out-of-domain truly clean corpus yields higher DNSMOS/UTMOS on both dev and test, albeit with some intelligibility trade-off under stronger suppression.
This clarifies discrepancies across prior unsupervised results and argues for careful, transparent prior selection when claiming SOTA on simulated benchmarks.
The proposed dual-branch encoder-decoder architecture treats enhancement as explicit two-source estimation with data-defined priors, not metric-chasing. The reconstruction constraint (clean + noise = input) plus adversarial priors over independent clean/noise corpora gives a clear inductive bias, and initializing from a neural audio codec is a pragmatic way to stabilize training. The results look competitive with unsupervised baselines while avoiding DNSMOS-guided objectives; the caveat is that “clean prior” choice materially affects reported gains, so claims should specify corpus selection.
Check out the PAPER. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.