The Latest Gemini 2.5 Flash-Lite Preview is Now the Fastest Proprietary Model (External Tests) and 50% Fewer Output Tokens
Google released an updated version of Gemini 2.5 Flash and Gemini 2.5 Flash-Lite preview models across AI Studio and Vertex AI, plus rolling aliases—gemini-flash-latest and gemini-flash-lite-latest—that always point to the newest preview in each family. For production stability, Google advises pinning fixed strings (gemini-2.5-flash, gemini-2.5-flash-lite). Google will give a two-week email notice before retargeting a -latest alias, and notes that rate limits, features, and cost may vary across alias updates.
What actually changed?
- Flash: Improved agentic tool use and more efficient “thinking” (multi-pass reasoning). Google reports a +5 point lift on SWE-Bench Verified vs. the May preview (48.9% → 54.0%), indicating better long-horizon planning/code navigation.
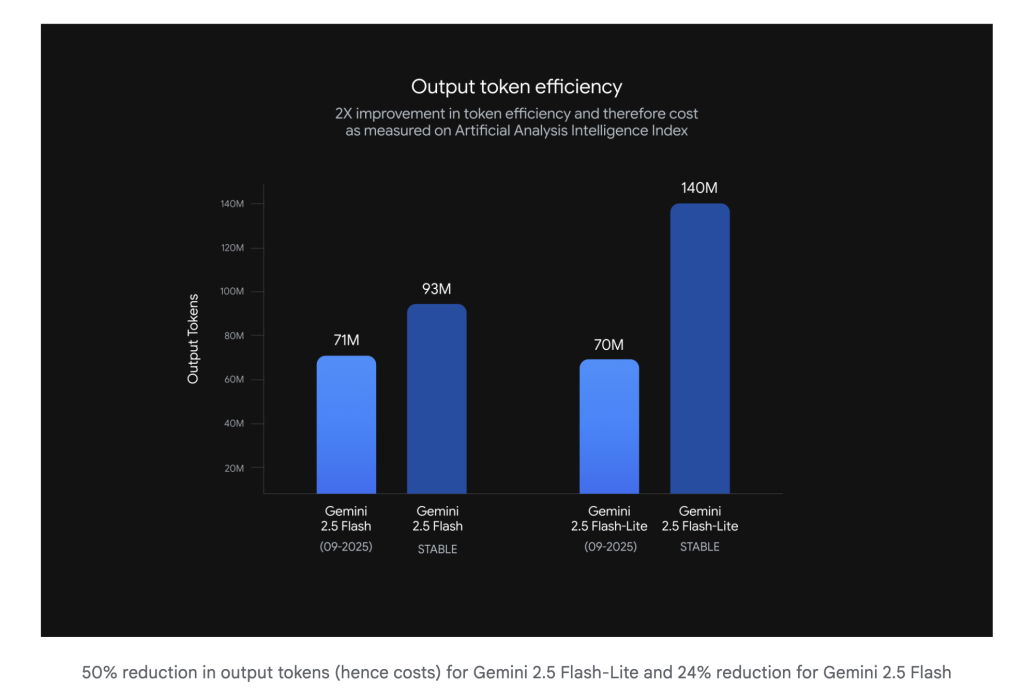
- Flash-Lite: Tuned for stricter instruction following, reduced verbosity, and stronger multimodal/translation. Google’s internal chart shows ~50% fewer output tokens for Flash-Lite and ~24% fewer for Flash, which directly cuts output-token spend and wall-clock time in throughput-bound services.
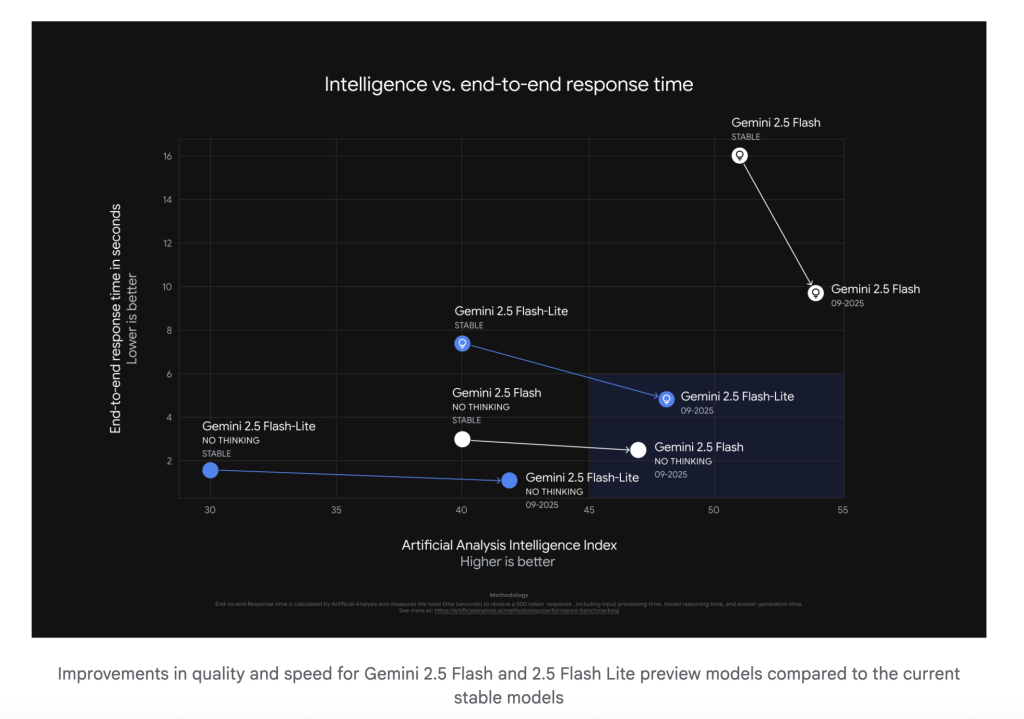
Artificial Analysis (the account behind the AI benchmarking site) received pre-release access and published external measurements across intelligence and speed. Highlights from the thread and companion pages:
- Throughput: In endpoint tests, Gemini 2.5 Flash-Lite (Preview 09-2025, reasoning) is reported as the fastest proprietary model they track, around ~887 output tokens/s on AI Studio in their setup.
- Intelligence index deltas: The September previews for Flash and Flash-Lite improve on Artificial Analysis’ aggregate “intelligence” scores compared with prior stable releases (site pages break down reasoning vs. non-reasoning tracks and blended price assumptions).
- Token efficiency: The thread reiterates Google’s own reduction claims (−24% Flash, −50% Flash-Lite) and frames the win as cost-per-success improvements for tight latency budgets.
Cost surface and context budgets (for deployment choices)
- Flash-Lite GA list price is $0.10 / 1M input tokens and $0.40 / 1M output tokens (Google’s July GA post and DeepMind’s model page). That baseline is where verbosity reductions translate to immediate savings.
- Context: Flash-Lite supports ~1M-token context with configurable “thinking budgets” and tool connectivity (Search grounding, code execution)—useful for agent stacks that interleave reading, planning, and multi-tool calls.
Browser-agent angle and the o3 claim
A circulating claim says the “new Gemini Flash has o3-level accuracy, but is 2× faster and 4× cheaper on browser-agent tasks.” This is community-reported, not in Google’s official post. It likely traces to private/limited task suites (DOM navigation, action planning) with specific tool budgets and timeouts. Use it as a hypothesis for your own evals; don’t treat it as a cross-bench truth.
Practical guidance for teams
- Pin vs. chase
-latest: If you depend on strict SLAs or fixed limits, pin the stable strings. If you continuously canary for cost/latency/quality, the-latestaliases reduce upgrade friction (Google provides two weeks’ notice before switching the pointer). - High-QPS or token-metered endpoints: Start with Flash-Lite preview; the verbosity and instruction-following upgrades shrink egress tokens. Validate multimodal and long-context traces under production load.
- Agent/tool pipelines: A/B Flash preview where multi-step tool use dominates cost or failure modes; Google’s SWE-Bench Verified lift and community tokens/s figures suggest better planning under constrained thinking budgets.
Model strings (current)
- Previews:
gemini-2.5-flash-preview-09-2025,gemini-2.5-flash-lite-preview-09-2025 - Stable:
gemini-2.5-flash,gemini-2.5-flash-lite - Rolling aliases:
gemini-flash-latest,gemini-flash-lite-latest(pointer semantics; may change features/limits/pricing).
Summary
Google’s new release update tightens tool-use competence (Flash) and token/latency efficiency (Flash-Lite) and introduces -latest aliases for faster iteration. External benchmarks from Artificial Analysis indicate meaningful throughput and intelligence-index gains for the Sept 2025. previews, with Flash-Lite now testing as the fastest proprietary model in their harness. Validate on your workload—especially browser-agent stacks—before committing to the aliases in production.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.