Liquid AI’s LFM2-VL-3B Brings a 3B Parameter Vision Language Model (VLM) to Edge-Class Devices
Liquid AI released LFM2-VL-3B, a 3B parameter vision language model for image text to text tasks. It extends the LFM2-VL family beyond the 450M and 1.6B variants. The model targets higher accuracy while preserving the speed profile of the LFM2 architecture. It is available on LEAP and Hugging Face under the LFM Open License v1.0.
Model overview and interface
LFM2-VL-3B accepts interleaved image and text inputs and produces text outputs. The model exposes a ChatML like template. The processor inserts an
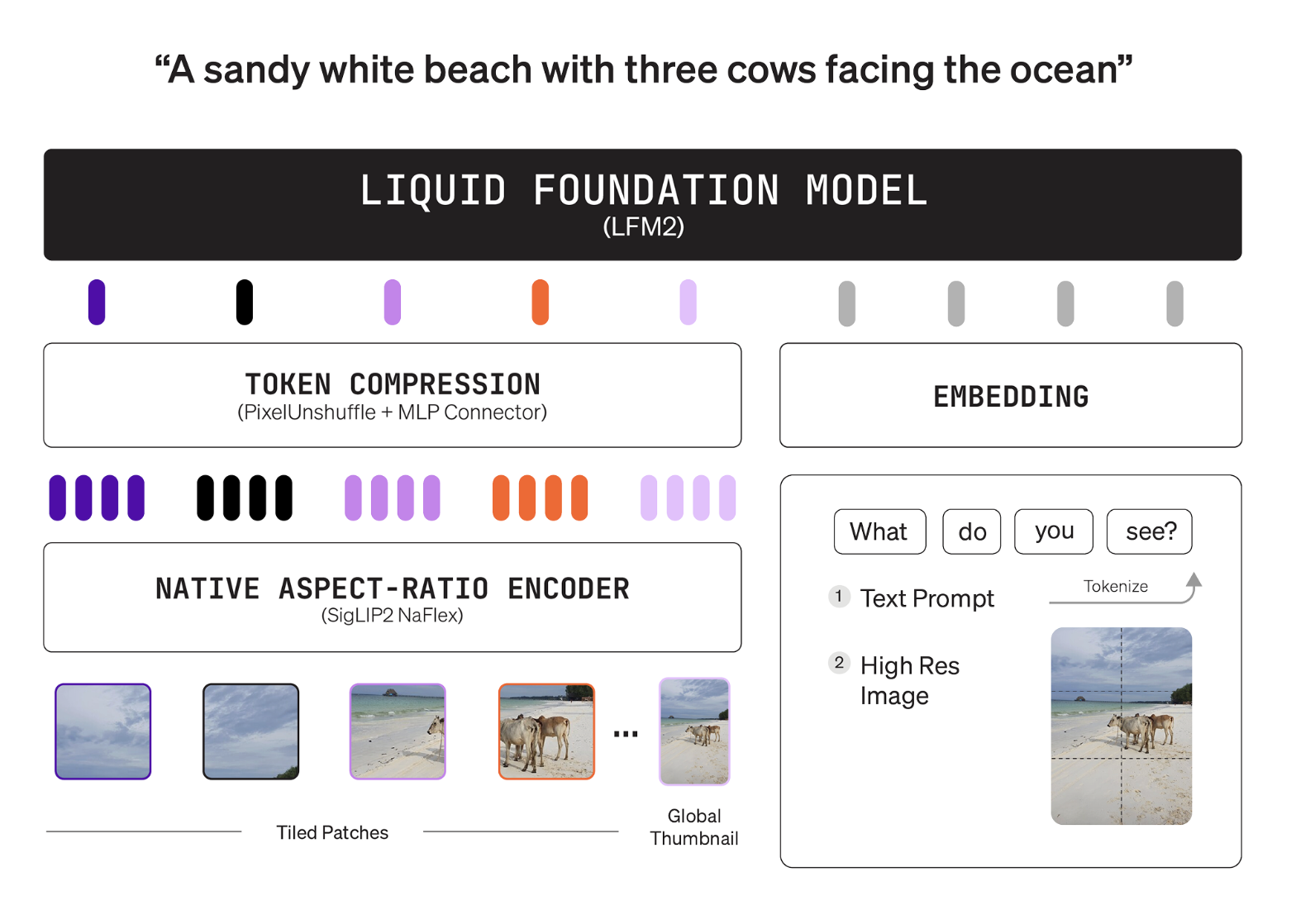
Architecture
The stack pairs a language tower with a shape aware vision tower and a projector. The language tower is LFM2-2.6B, a hybrid convolution plus attention backbone. The vision tower is SigLIP2 NaFlex at 400M parameters, it preserves native aspect ratios and avoids distortion. The connector is a 2 layer MLP with pixel unshuffle, it compresses image tokens before fusion with the language space. This design lets users cap vision token budgets without retraining the model.
The encoder processes native resolutions up to 512×512. Larger inputs are split into non overlapping 512×512 patches. A thumbnail pathway provides global context during tiling. The efficient token mapping is documented with concrete examples, a 256×384 image maps to 96 tokens, a 1000×3000 image maps to 1,020 tokens. The model card exposes user controls for minimum and maximum image tokens and the tiling switch. These controls tune speed and quality at inference time.
Inference settings
The Hugging Face model card provides recommended parameters. Text generation uses temperature 0.1, min p 0.15, and a repetition penalty of 1.05. Vision settings use min image tokens 64, max image tokens 256, and image splitting enabled. The processor applies the chat template and the image sentinel automatically. The example uses AutoModelForImageTextToText and AutoProcessor with bfloat16 precision.
How is it trained?
Liquid AI describes a staged approach. The team performs joint mid training that adjusts the text to image ratio over time. The model then undergoes supervised fine tuning focused on image understanding. The data sources are large scale open datasets plus in house synthetic vision data for task coverage.
Benchmarks
The research team reports competitive results among lightweight open VLMs. On MM-IFEval the model reaches 51.83. On RealWorldQA it reaches 71.37. On MMBench dev en it reaches 79.81. The POPE score is 89.01. The table notes that scores for other systems were computed with VLMEvalKit. The table excludes Qwen3-VL-2B because that system was released one day earlier.
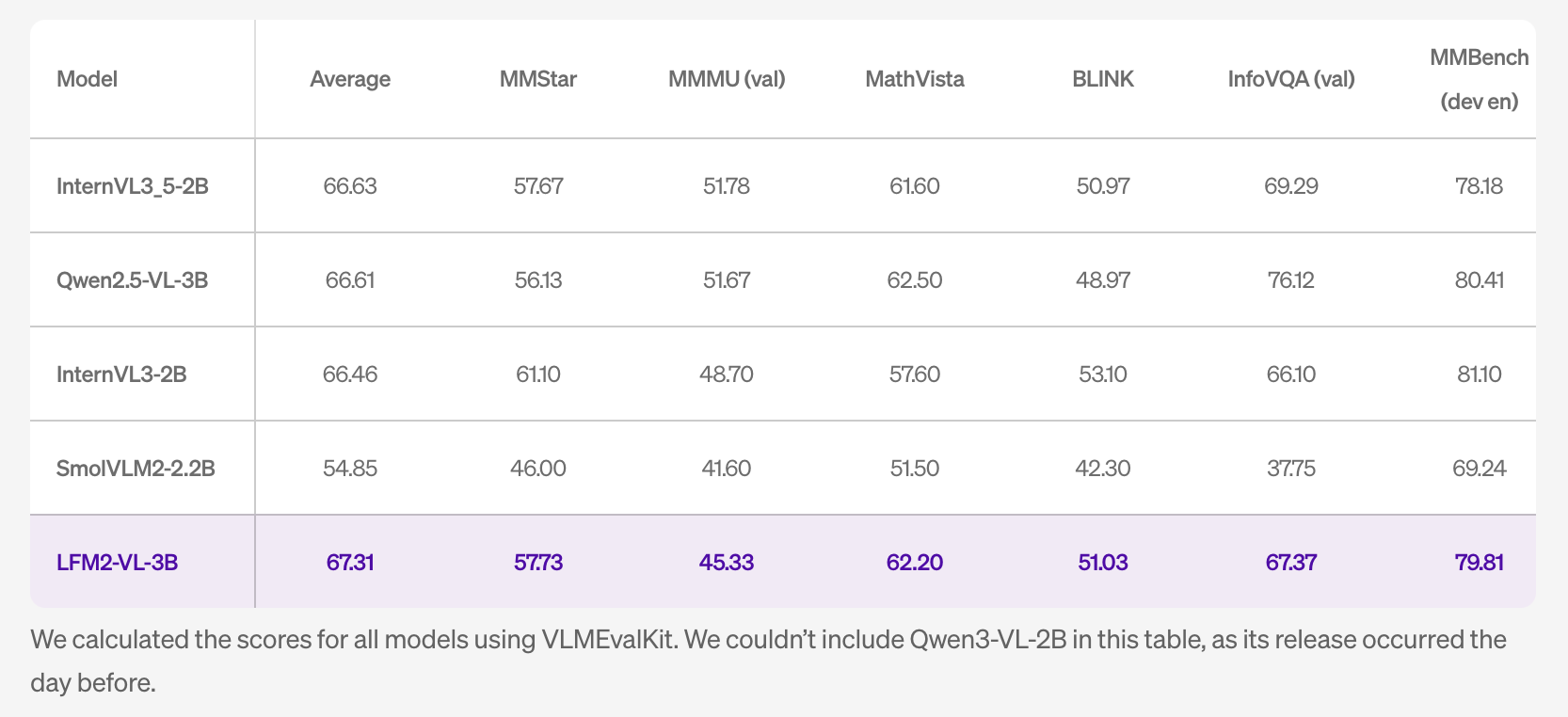
The language capability remains close to the LFM2-2.6B backbone. The research team cites 30 percent on GPQA and 63 percent on MMLU. This matters when perception tasks include knowledge queries. The team also states expanded multilingual visual understanding across English, Japanese, French, Spanish, German, Italian, Portuguese, Arabic, Chinese, and Korean.
Why edge users should care?
The architecture keeps compute and memory within small device budgets. Image tokens are compressible and user constrained, so throughput is predictable. SigLIP2 400M NaFlex encoder preserves aspect ratios, which helps fine grained perception. The projector reduces tokens at the connector, which improves tokens per second. The research team also published a GGUF build for on device runtimes. These properties are useful for robotics, mobile, and industrial clients that need local processing and strict data boundaries.
Key Takeaways
- Compact multimodal stack: 3B parameter LFM2-VL-3B pairs an LFM2-2.6B language tower with a 400M SigLIP2 NaFlex vision encoder and a 2-layer MLP projector for image-token fusion. NaFlex preserves native aspect ratios.
- Resolution handling and token budgets: Images run natively up to 512×512, larger inputs tile into non overlapping 512×512 patches with a thumbnail pathway for global context. Documented token mappings include 256×384 → 96 tokens and 1000×3000 → 1,020 tokens.
- Inference interface: ChatML-like prompting with an
- Measured performance: Reported results include MM-IFEval 51.83, RealWorldQA 71.37, MMBench-dev-en 79.81, and POPE 89.01. Language-only signals from the backbone are about 30% GPQA and 63% MMLU, useful for mixed perception plus knowledge workloads.
LFM2-VL-3B is a practical step for edge multimodal workloads, the 3B stack pairs LFM2-2.6B with a 400M SigLIP2 NaFlex encoder and an efficient projector, which lowers image token counts for predictable latency. Native resolution processing with 512 by 512 tiling and token caps gives deterministic budgets. Reported scores on MM-IFEval, RealWorldQA, MMBench, and POPE are competitive for this size. Open weights, a GGUF build, and LEAP access reduce integration friction. Overall, this is an edge ready VLM release with clear controls and transparent benchmarks.
Check out the Model on HF and Technical details. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.